
サービスデスクへの問い合わせを減らすSparkの5つの活用事例

サービスデスクの「変革」というと、通常はチケットの処理を迅速化することを意味しますが、実際に必要なのは、そもそものチケットの発生自体を減らすことです。
Gartnerの予測によると、エージェント型AIが2029年までに一般的なカスタマーサービスの問題の80%を自律的に解決し、運用コストを30%削減する見込みです。つまり、「摩擦のない職場環境」への転換が起きており、そこでは従業員が通常業務に戻るためだけにサポート窓口を利用する必要がなくなります。
ほとんどのITチームでは、まずL1(レベル1)の問い合わせを減らすことが重要です。 その内容の多くは予測しやすく、IT部門がすでに解決方法を知っているにもかかわらず、依然として毎日手作業で処理している問題です。しかし、多くの組織では、サポート体制そのものの構造を変えずに、既存のワークフローにAIが組み込まれているだけです。これではリクエストの処理は迅速化できても、受付の仕組みは変わりません。従業員は相変わらずチケットを作成し続け、その引き継ぎの後に対処が行われるため、見慣れた仕事がキュー内で積み上がっていきます。
Sparkは、対処のスタート地点を変えます。Sparkは、NexthinkのリアルタイムDEXテレメトリおよび修復エンジンを基盤としており、従業員のデバイス、アプリケーション、およびネットワークにわたるコンテキストデータに即座にアクセスできます。このデータにはデバイスの健全性、アプリのパフォーマンス、VPNアクセス、接続状況などのシグナルが含まれます。そしてリアルタイムのコンテキストを基に問題を診断し、IT部門が承認したアクションを、既存の管理体制の範囲内で実行します。Sparkは、繰り返し発生する問題を直接解決し、受付を待つ必要がないため、L1の不要なやり取りを減らし、そのような作業自体をキューから完全になくすことができます。
1. チケットを作成せずに、繰り返し発生するコラボレーション上の問題を解決
多くの大規模組織では、日常的に使われているコラボレーションツールから、些細ながらもコンスタントな問題が発生し続けて業務を妨げ、サービスデスクを悩ませることになります。症状はケースによって異なりますが、通常、その根本原因は限られており、デバイスの状態、ネットワーク環境、あるいはユーザーの状況に関連する問題です。 従業員にとっては新しい問題のように感じられても、サービスデスクにとってはこれまで何十回も経験してきた問題であることが普通です。
Sparkを問題解決の起点とすれば、チケットの発行自体をプロセスからなくせます。 従業員からコラボレーション関連の問題が報告されたら、Sparkがそのデバイス上で何が起きているかをリアルタイムで確認し、アプリケーションが最新の状態であるか、ネットワークのパフォーマンスはどうか、そしてデバイス全体の動作状況がどうなっているかを分析します。承認済みの修正プログラムが利用可能な場合は、IT部門があらかじめ設定した範囲内で、Sparkがそれを直ちに実行します。 従業員は即座にサポートを受けられ、サービスデスクは、いつものよくある問題について、毎回同じ時間がかかるトラブルシューティングの手順を繰り返す必要がなくなります。
実際の画面を以下に示します。
Sparkが、通話品質の低下を検知し、ネットワークとTeamsクライアントの状態を確認した上で、承認済みの是正措置を適用し、その場ですぐに通話品質を回復させます。
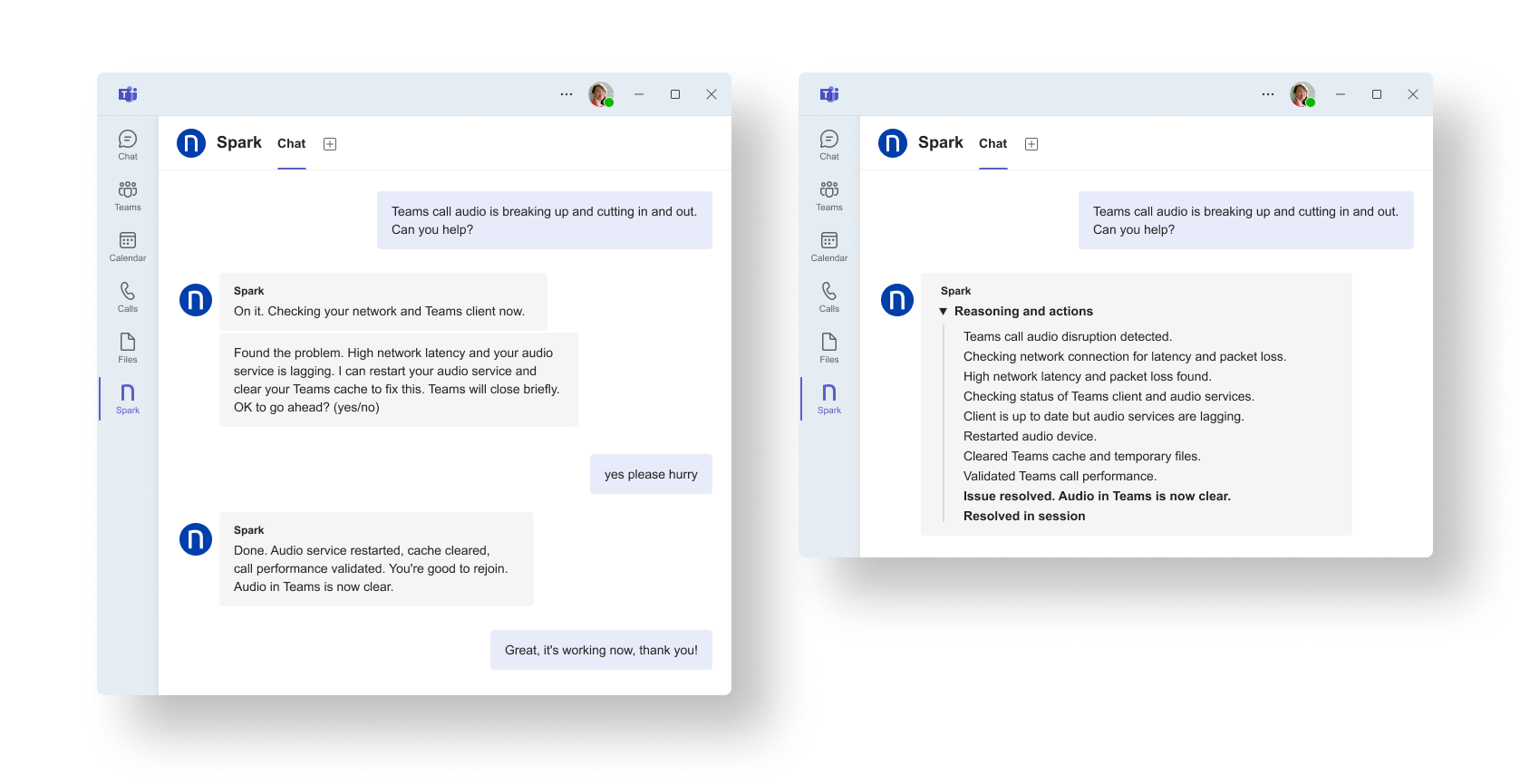
時間の経過とともに、かつてL1のリソースを消費し続けていた問題のカテゴリ自体がほぼ自律的な解決のフローへと移行し、これによりチケットの数が減少し、チケット発行後にいつも繰り返し行われていたトラブルシューティングも不要になります。
2. セッション中のエンドポイントのパフォーマンスを診断し、問題を解決
大規模な環境では、エンドポイントのパフォーマンスに関する問題が頻繁に発生します。特に、時間の経過とともにデバイスの状態が当初の基準値からずれていくにつれて、その傾向は顕著になります。典型的な例として、起動やログインが遅くなることが挙げられます。 以前はすぐに仕事に取りかかれたのに、バックグラウンドで実行される処理が増えてリソースを奪い合う結果、数分の待ち時間が生じます。従来のサポートモデルでは、アナリストがまずユーザーからの説明を基に、チケットを作成します。 その後に初めて、CPU、メモリ、ディスク、およびプロセスのデータを収集し、どのような措置を講じるかを決定します。
Sparkは、その手順の起点が異なります。なぜならSparkは、リアルタイムのエンドポイントテレメトリを処理し、従業員が操作を開始した瞬間のデバイスの状態を評価することができるためです。これにより、リソースの利用状況、起動時の影響、およびプロセスの異常な挙動を、事後ではなくリアルタイムで評価することができます。 あらかじめ定義された閾値が満たされ、承認済みの是正措置が利用可能な場合、Sparkはその是正措置を直接実行するか、Flowを通じて構造化されたワークフローを開始します。
実際の画面を以下に示します。
Sparkが、起動を遅らせているバックグラウンドプロセスを特定し、メモリ負荷を解消した上で、是正措置の実施後のパフォーマンスを確認します。そのため従業員はチケットを発行せずに通常業務に復帰できます。
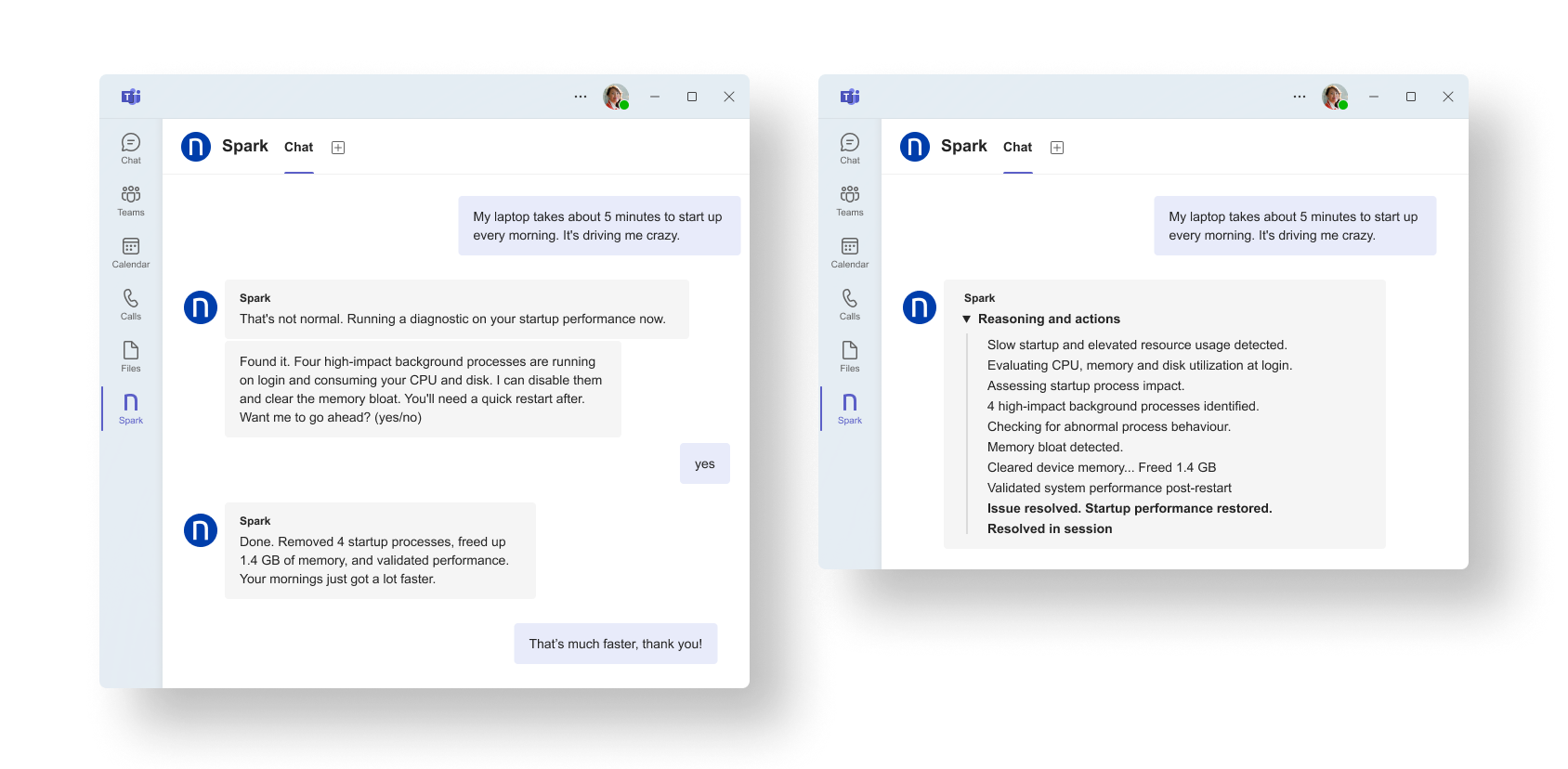
その結果、診断・是正措置の手順が確立されている問題については、手動でのデータ収集やチケット作成が不要となり、IT部門があらかじめ定めた手順の範囲内で即座に対処することが可能になります。
3. L1の繰り返し発生する問題を、キューに到達する前に解決
多くの企業では、L1の問題の大部分は、ポリシー同期エラー、基本設定のリセット、権限の更新、クライアントの再起動といった繰り返し発生する問題のカテゴリに該当します。こうした問題が発生し続ける原因は、通常、技術的な複雑さではなく、ワークフローの設計にあります。
Sparkは既存のセルフサービスチャネルに組み込まれ、従業員がサポートを依頼すると対応します。 その従業員による操作をきっかけとして、Sparkはチケットが作成される前に完全な問題解決を図ります。エンドポイントのコンテキストを分析し、エージェントアクションを適用して管理することにより、サポート対応の中で繰り返し発生する問題を処理します。 IT部門は、いつものよくある問題を再びキューに追加する代わりに、その問題をキューから完全になくすことが可能になります。
実際の画面を以下に示します。
Sparkが、Outlookクライアントのよくある障害を検知し、承認済みの再起動およびキャッシュクリア処理を実行することにより、稼働中のアプリケーションをすぐに正常な状態に戻します。
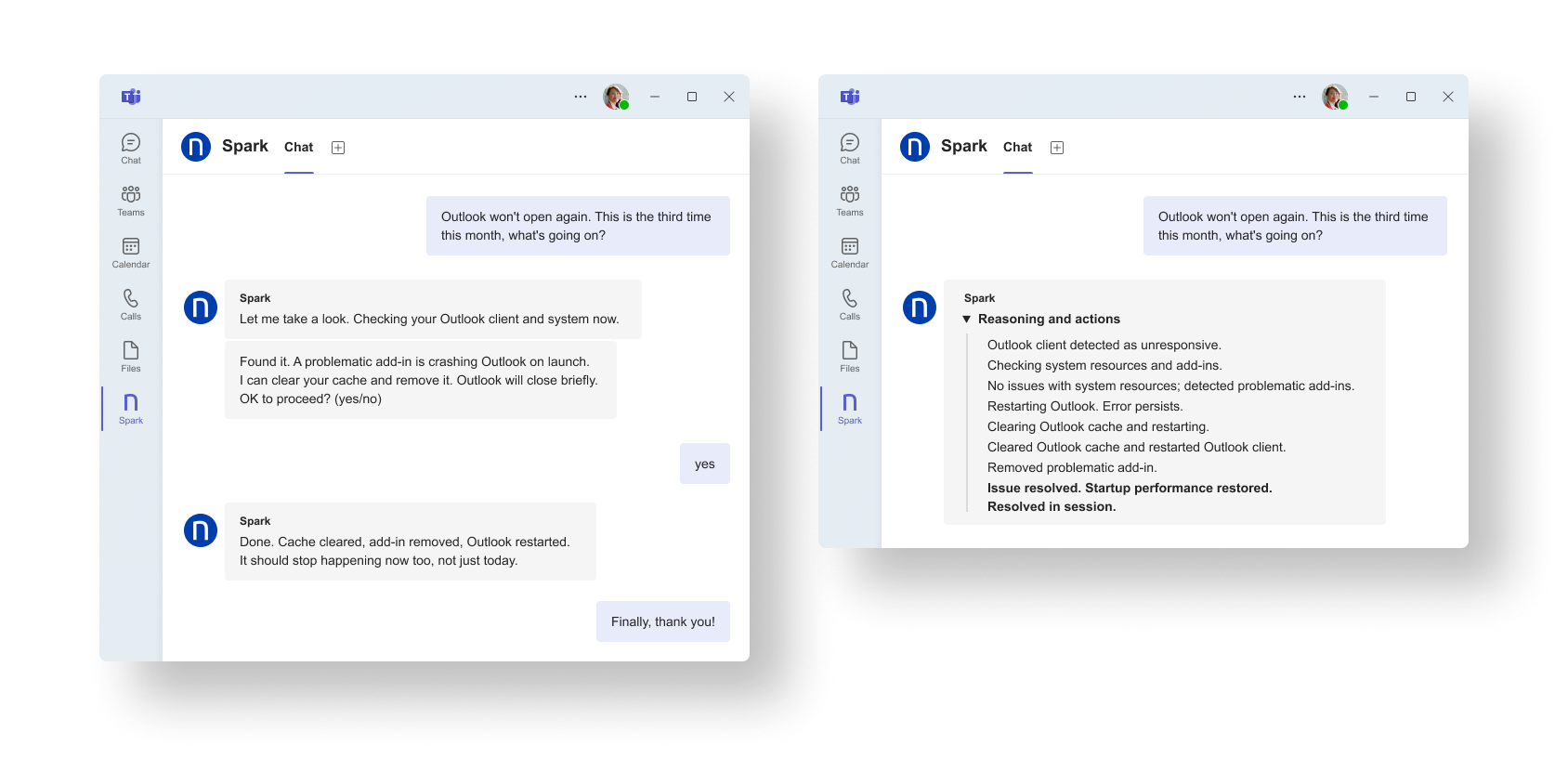
予測可能なカテゴリの問題は自動的に処理されるため、チケットの受付件数は時間の経過とともに減少します。 「ゼロ摩擦」が単なる理想にとどまらず、具体的な指標として測定可能になります。その成果は、L1の件数の減少や、人的サポートが必要な場面における問題の初回解決率の向上という形で現れます。
4. アクセス途絶の瞬間に、従業員のオンライン接続を復旧
従業員がIT部門に抱く印象は、多くの場合、アクセス障害やログインのループなど、業務の妨げとなる出来事によって決まりがちです。こうした問題は早急に対処する必要があり、摩擦が大きく、解決するのが難しいチケットが作成されてしまいます。問題の性質上、従業員が安全に自己診断を行うことができない上、サービスデスクもデータではなく質問から手順を始めざるを得ません。
Sparkは、まさにそのようなケースのために設計されています。 アクセスに関する問題が従業員から報告されると、Sparkは現在の接続状況やデバイスの状態をリアルタイムで確認し、検知内容に基づき、承認済みの解決手順に従って対応を行います。問題の状況が既知のパターンと一致する場合、従業員は、基本的な診断や度重なる引き継ぎを伴うサポートプロセスを開始しなくても、即座に問題が解消され、通常業務に戻れます。
実際の画面を以下に示します。
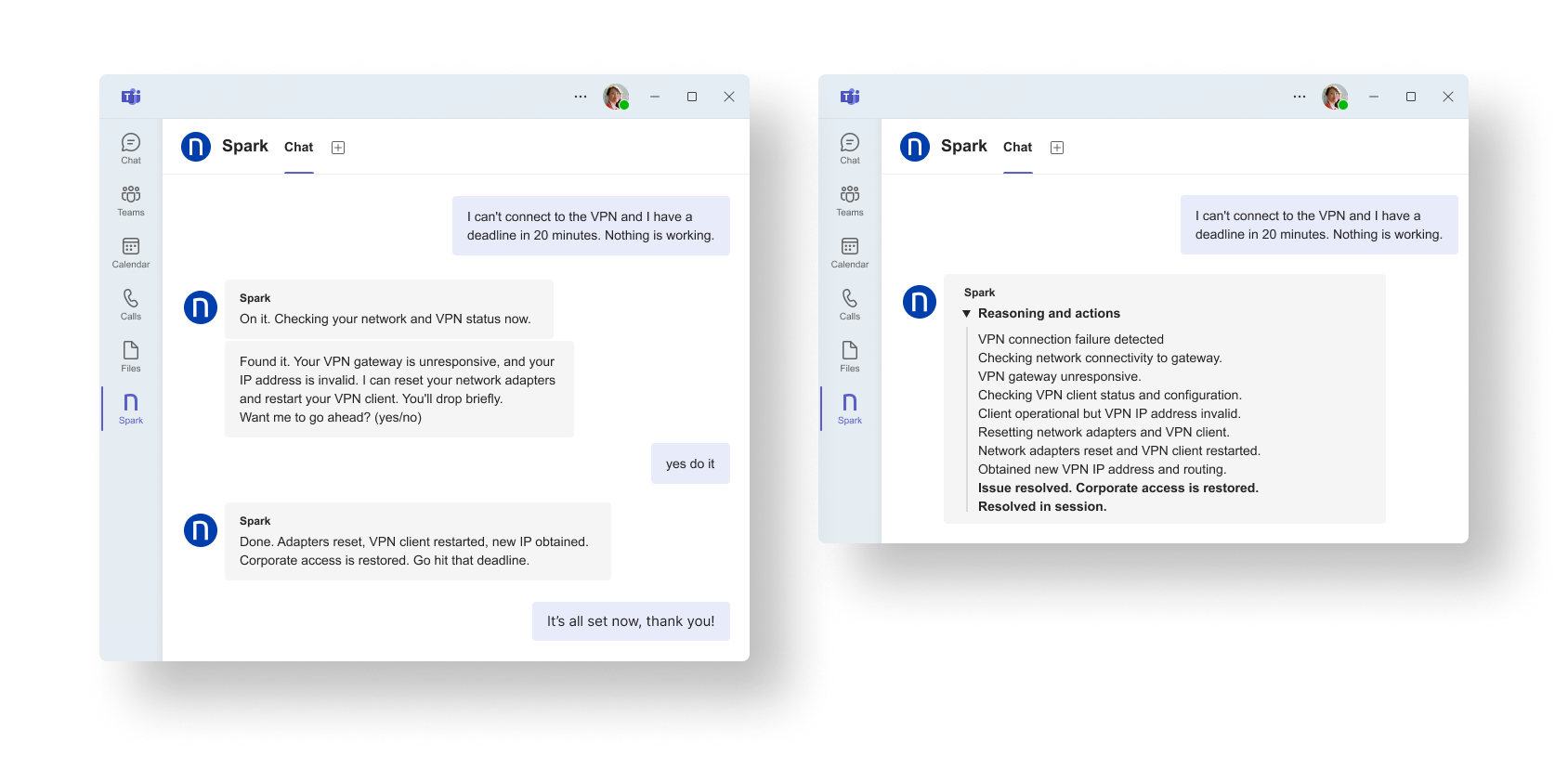
その効果は、従業員エクスペリエンスの向上だけにとどまりません。サービスデスクも、既知の問題への対処に費やす時間を減らし、人間の判断が真に必要とされる業務により多くの時間を割けるようになります。
5. 「ノートパソコンの動作が遅い」だけでチケットが作成されるのを防止
パフォーマンスに関する苦情は、サービスデスクによく届きます。なぜなら、これは現実的かつ主観的な問題であると同時に、通常、明らかな不具合というよりは、これまで徐々に生じてきた変化の結果であるからです。
チケットが作成される段階では、すでに「質問→ログの収集→対応待ち→修正の試行→繰り返し」という時間のかかるループに陥っているのです。
Sparkは、デバイスの状態のリアルタイム評価から開始することで、そのパターンを短縮させます。 パフォーマンス低下が従業員から報告された場合、Sparkはその時点での状況評価を行い、パフォーマンス低下の一般的な原因を特定した後、承認済みの是正手順に従って対応することができます。
これにより、長引くサポート対応から、正確なリアルタイムのデータに基づいた迅速な問題解決へとプロセスを刷新できます。
実際の画面を以下に示します。
Sparkが、CPUとメモリのリアルタイムな負荷状況を検知し、リソース競合の原因を取り除きます。そしてシステムパフォーマンスが回復したことを確認してからインタラクションを終了します。
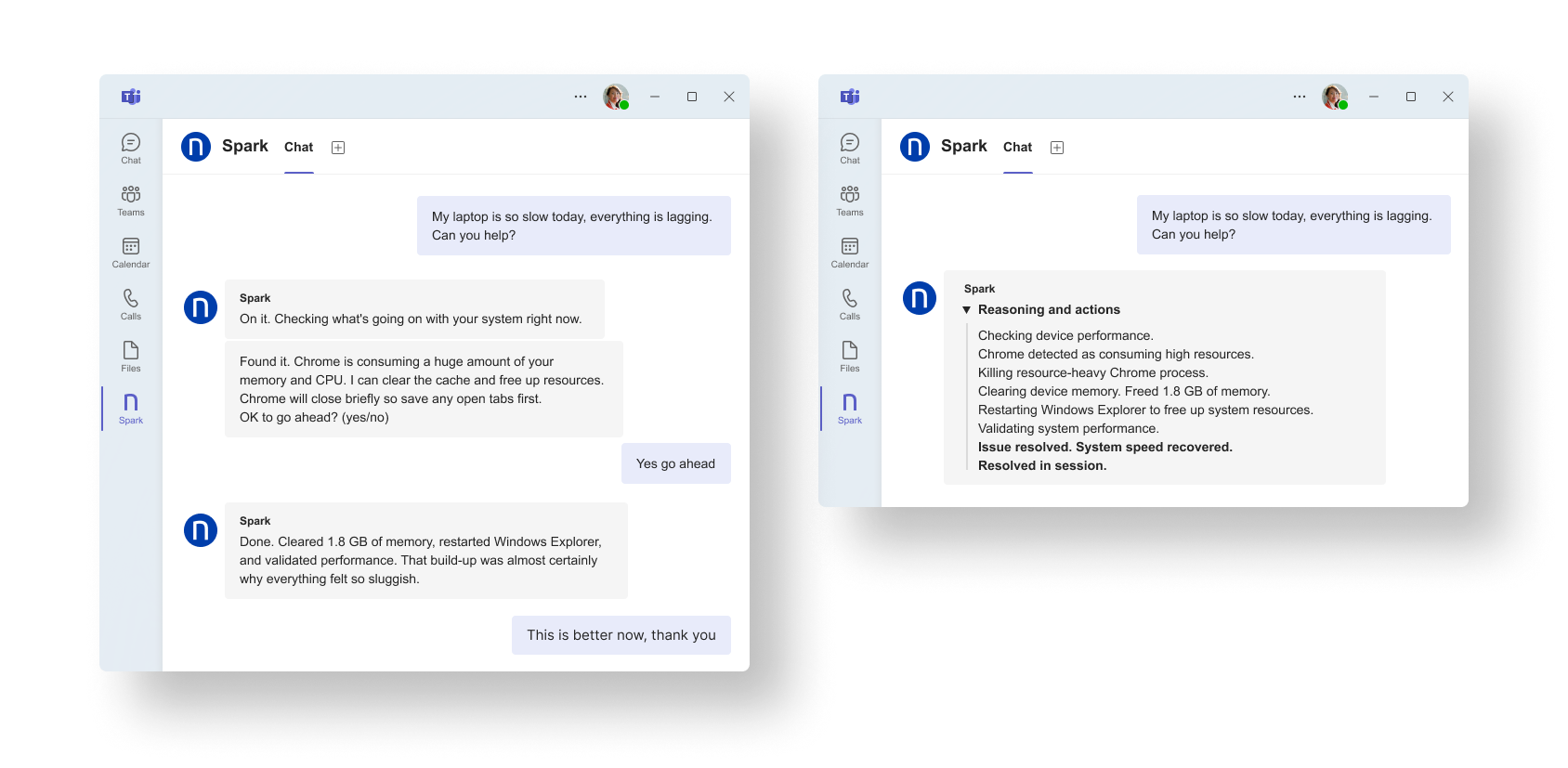
Sparkの強みは、IT部門がすでに解決方法を知っているにもかかわらず、依然として毎日手作業で処理している問題に対処できることです。デバイスの動作が遅いという苦情は、まさにそのパターンに当てはまります。 エンドポイントのシグナルはすでに存在しており、通常、是正措置の道筋もすでに明確に定められています。Sparkはそうしたリアルタイムのコンテキストを基にパターンを認識し、従業員とのやり取りの最中に修正を実行するため、チケットの作成自体が不要になります。
サービスデスクで繰り返し発生する問題を解消
Sparkは、L1の問い合わせの件数を増やし続けている多くの繰り返し発生する問題に対応できますが、その効果は計り知れません。ほとんどの環境では、比較的少数の反復的な問題、コラボレーションの不安定さ、エンドポイントのパフォーマンスの低下、そして設定の長期的なずれが、サービスデスクへの問い合わせの大半を占めています。
こうした問題が、キューに追加されずに自律的にリアルタイムで処理されるようになれば、その影響は構造的な転換をもたらします。チケット件数が減少し、問題解決が迅速化され、サービスデスクの業務も反復作業から付加価値の高い業務へとシフトします。 問題は、チケットをどれだけ迅速に解決できるかではなく、そもそもそれらのチケットをサービスデスクへ届ける必要があるか、という点です。
貴社では、繰り返し発生するL1の問題を解消することで、どのような効果が得られるでしょうか?Sparkの詳細については、今すぐNexthinkのデモをご依頼ください。
