
Support IT : 5 cas d’usage Spark qui réduisent le volume de tickets

En général, les services de support IT se fixent pour objectif d'accélérer les délais de traitement des tickets. Pourtant, le véritable enjeu est ailleurs : réduire, en amont, les causes mêmes menant à la création desdits tickets.
Gartner anticipe que, d'ici à 2029, l’IA agentique résoudra de manière autonome 80 % des problèmes IT courants, avec à la clé, une réduction de 30 % des coûts opérationnels. Cette évolution ouvre la voie à une Digital Workplace sans friction, dans laquelle les collaborateurs n’ont plus à dépendre du support et de ses processus complexes pour poursuivre leur travail.
Pour la plupart des équipes IT, l’opportunité se situe d’abord au niveau du volume de tickets L1. Une grande partie de ces tickets est prévisible : ce sont des problèmes que les équipes savent déjà corriger, mais qu’elles traitent encore manuellement, jour après jour. Pourtant, dans de nombreuses entreprises, l’IA s’est greffée aux workflows existants sans en transformer réellement la structure. Les demandes circulent peut-être plus vite, mais le modèle d’entrée reste inchangé : le collaborateur ouvre un ticket, la résolution commence après le transfert, et les mêmes tâches continuent de s’accumuler en file d’attente.
C’est là que Spark change la donne. Fondé sur la télémétrie DEX en temps réel et le moteur de résolution de Nexthink, notre agent IA accède instantanément aux données contextuelles du poste de travail, des applications et du réseau du collaborateur. Il analyse l’état des équipements, les performances applicatives, l’accès VPN et la qualité de la connectivité. En exploitant ce contexte en temps réel, Spark diagnostique les dysfonctionnements et exécute des actions autorisées par l’IT dans les cadres existants. Au lieu d’attendre l’ouverture d’un ticket, il traite directement les problèmes récurrents. Résultat : moins d’interactions inutiles de niveau 1 et une file d’attente plus courte.
1. Résoudre les problèmes de collaboration récurrents sans créer de ticket
Dans les grandes entreprises, les outils de collaboration génèrent au quotidien un flux constant de dysfonctionnements mineurs, mais non moins perturbants, qui finissent tous entre les mains du support IT. Si les symptômes varient en apparence, ils relèvent d’un petit nombre de situations déjà bien identifiées, liées à l’état du matériel, à la qualité du réseau ou au contexte de l'utilisateur. Ce qui paraît inédit pour le collaborateur est généralement bien connu du support.
Avec Spark comme premier point de contact, le processus ne commence plus par un ticket. Lorsqu’un collaborateur signale un problème avec un outil de collaboration, Spark inspecte le poste de travail en temps réel et vérifie la mise à jour de l’application, les performances du réseau et le comportement global de l’équipement. Si une solution validée existe, Spark l'applique immédiatement dans le cadre défini par l’IT. Le collaborateur reçoit une assistance immédiate, sans avoir à mobiliser l’équipe support pour résoudre un problème courant.
Dans la pratique :
Spark détecte une dégradation de la qualité d’appel, vérifie la connectivité et l’état du client Teams, applique la correction approuvée pour rétablir la qualité de communication dans la même interaction.
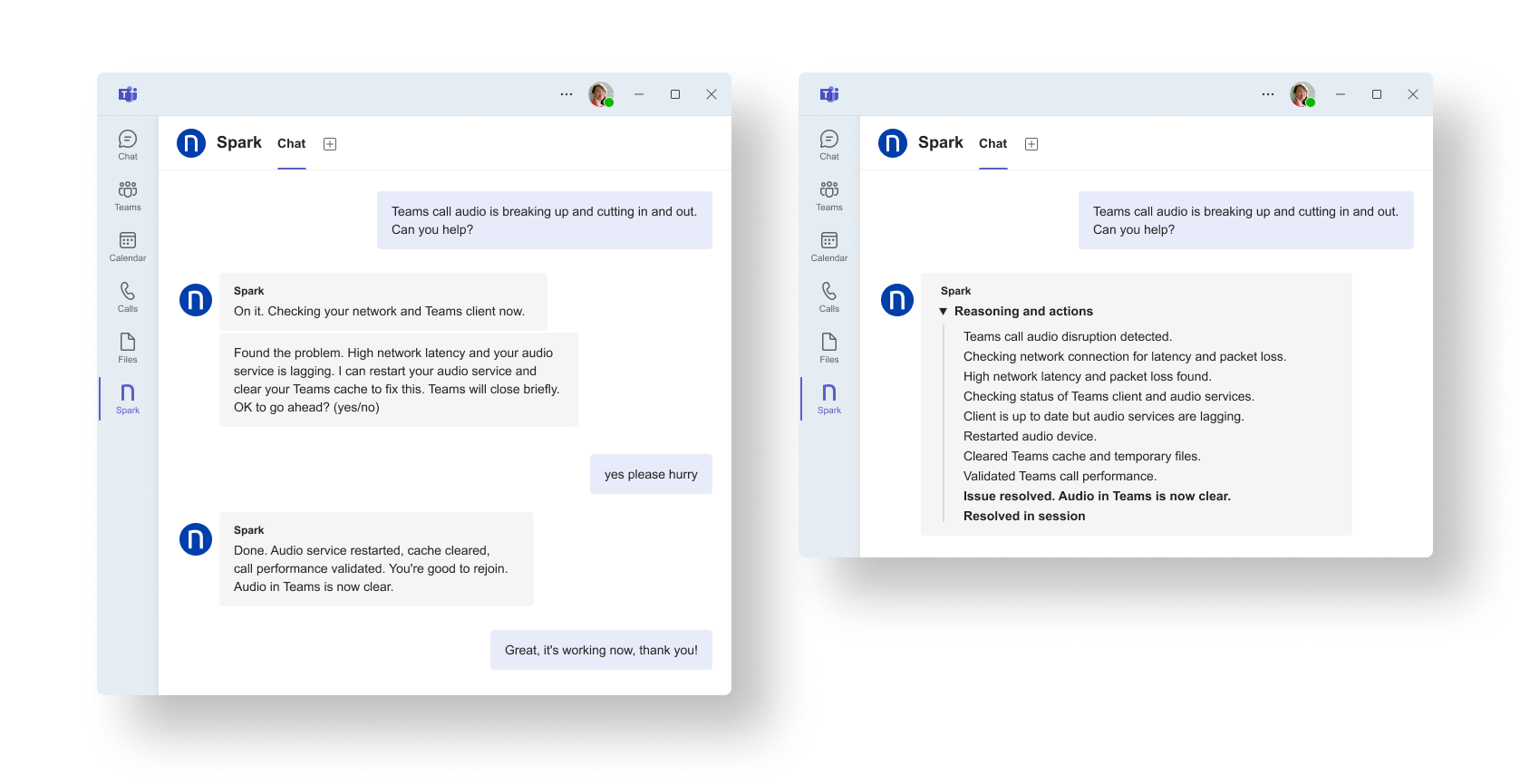
Avec le temps, les problèmes courants, autrefois chronophages pour le support L1, se résolvent en toute autonomie, ce qui permet de réduire le volume de tickets et les interventions répétitives.
2. Diagnostiquer et corriger les problèmes de performance des postes de travail pendant la session
Les problèmes de performance des postes de travail sont fréquents dans les environnements de grande envergure, notamment à mesure que les équipements s’éloignent de leur niveau de performance initial. Le cas typique est celui d'un démarrage lent. Au lieu d’être instantanée, la mise en route dure plusieurs minutes, ralentie par des processus s'exécutant en arrière-plan. Dans un modèle classique, l’analyse débute lorsque le collaborateur signale le problème et ouvre un ticket. Ce n’est qu’à ce moment-là que les équipes recueillent les données techniques (CPU, mémoire, disque et processus) nécessaires pour orienter la décision.
Spark transforme cette logique. En s’appuyant sur une télémétrie en temps réel, il évalue immédiatement l’état du poste de travail dès le début de l’interaction : utilisation des ressources, impact au démarrage, comportement anormal des processus… Si certains critères sont atteints et qu’une résolution validée existe, il applique directement la mesure corrective ou déclenche un workflow structuré via Flow.
Dans la pratique :
Spark identifie les processus en arrière-plan responsables du ralentissement, libère les ressources mémoire et vérifie le retour à une performance normale. Le collaborateur peut alors reprendre son activité, sans avoir à ouvrir un ticket.
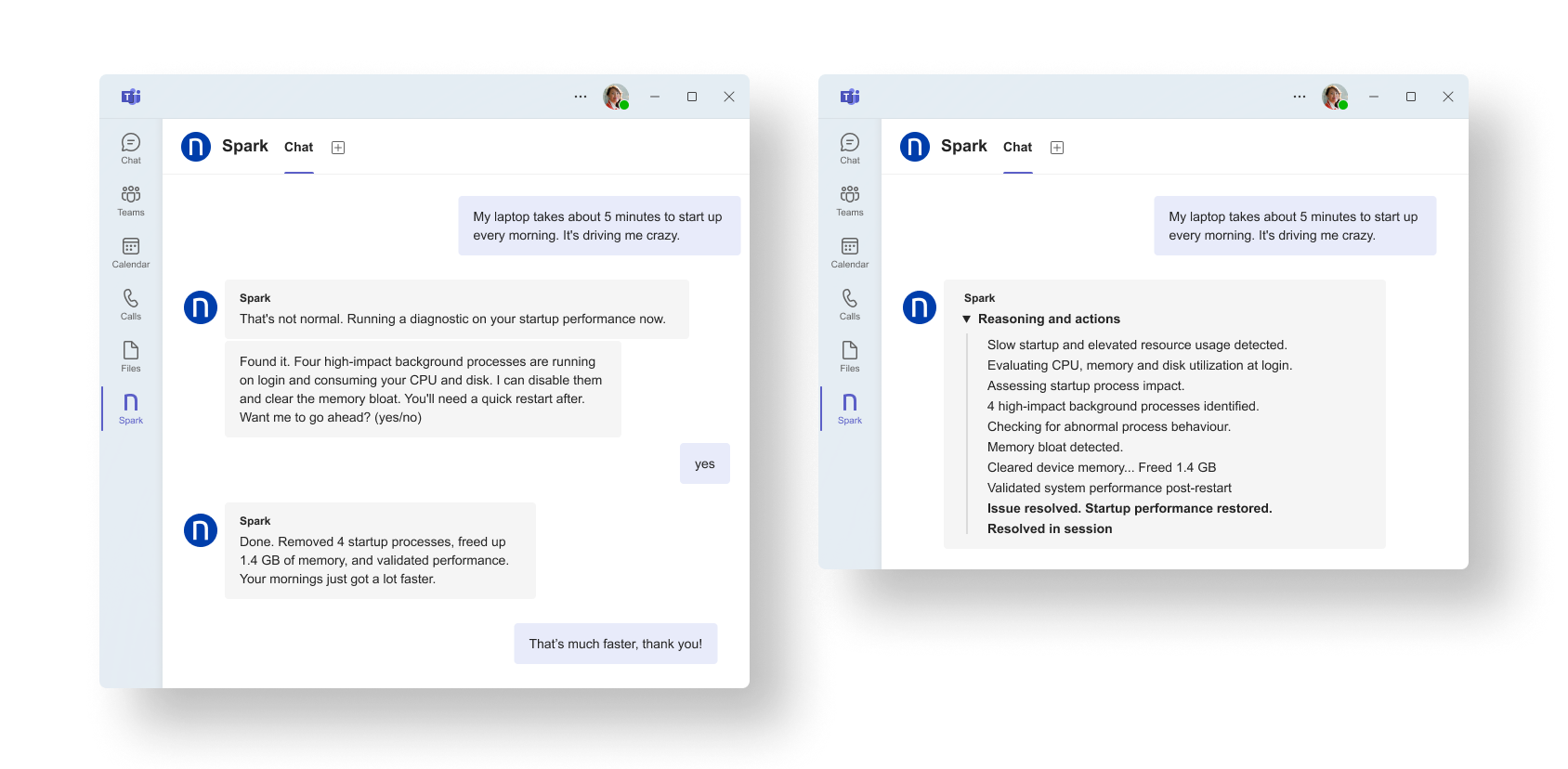
Résultat : les problèmes disposant d’un diagnostic et d’une correction connus sont traités instantanément, selon un cadre bien défini, sans collecte de données manuelle ni création de ticket.
3. Résoudre les problèmes L1 courants en amont
Dans la plupart des entreprises, une part importante du volume de tickets L1 correspond à des problèmes récurrents : erreurs de synchronisation des politiques, réinitialisations des configurations de base, actualisations des droits ou redémarrages applicatifs. Leur persistance tient moins à leur complexité technique qu’à l’organisation des workflows.
Spark s’intègre aux canaux de self-service existants et intervient dès qu’un collaborateur sollicite de l’aide. Avant même la création d’un ticket, il tente une résolution complète. Il s’appuie sur le contexte du poste de travail, exécute des actions encadrées et traite les incidents récurrents directement au cœur de l’échange. Plutôt que d’alimenter une nouvelle fois la file d’attente avec un problème récurrent, l’IT peut tout simplement l’éliminer en amont.
Dans la pratique :
Spark détecte un dysfonctionnement connu d’Outlook, exécute les actions validées (redémarrage, nettoyage du cache) et rétablit l’application pendant la session.
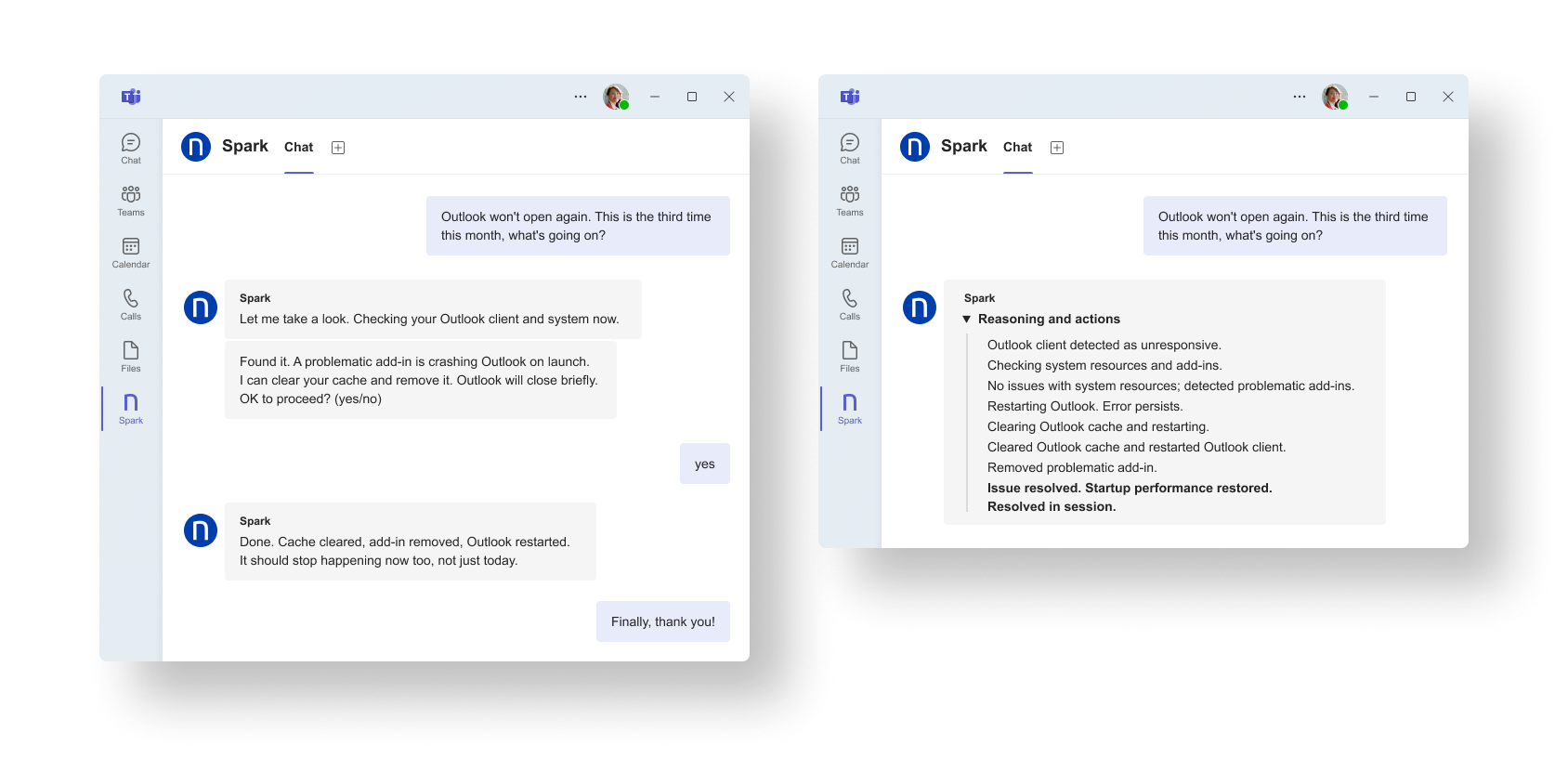
Au fil de la résolution autonome de ces problèmes prévisibles, le volume de tickets diminue. L’objectif d’une Digital Workplace sans friction se concrétise et se mesure désormais en chiffres, avec la baisse du volume de tickets L1 et l’amélioration du taux de résolution au premier contact lorsque l’intervention humaine reste nécessaire.
4. Rétablir l’accès en cas de coupure de connexion
La perception de l’IT par les collaborateurs se joue souvent dans les moments de blocage tels que les échecs de connexion ou les boucles d’authentification interminables. Ces situations critiques, où chaque minute compte, génèrent des tickets complexes, faute de diagnostic fiable côté utilisateur et de données concrètes côté support.
Spark est justement conçu pour ces situations. Lorsqu’un problème d’accès est signalé, il analyse en temps réel l’état de la connexion et du poste, puis applique la résolution prévue. Si le problème correspond à un scénario connu, il débloque immédiatement la situation, sans passer par un parcours de support classique.
Dans la pratique :
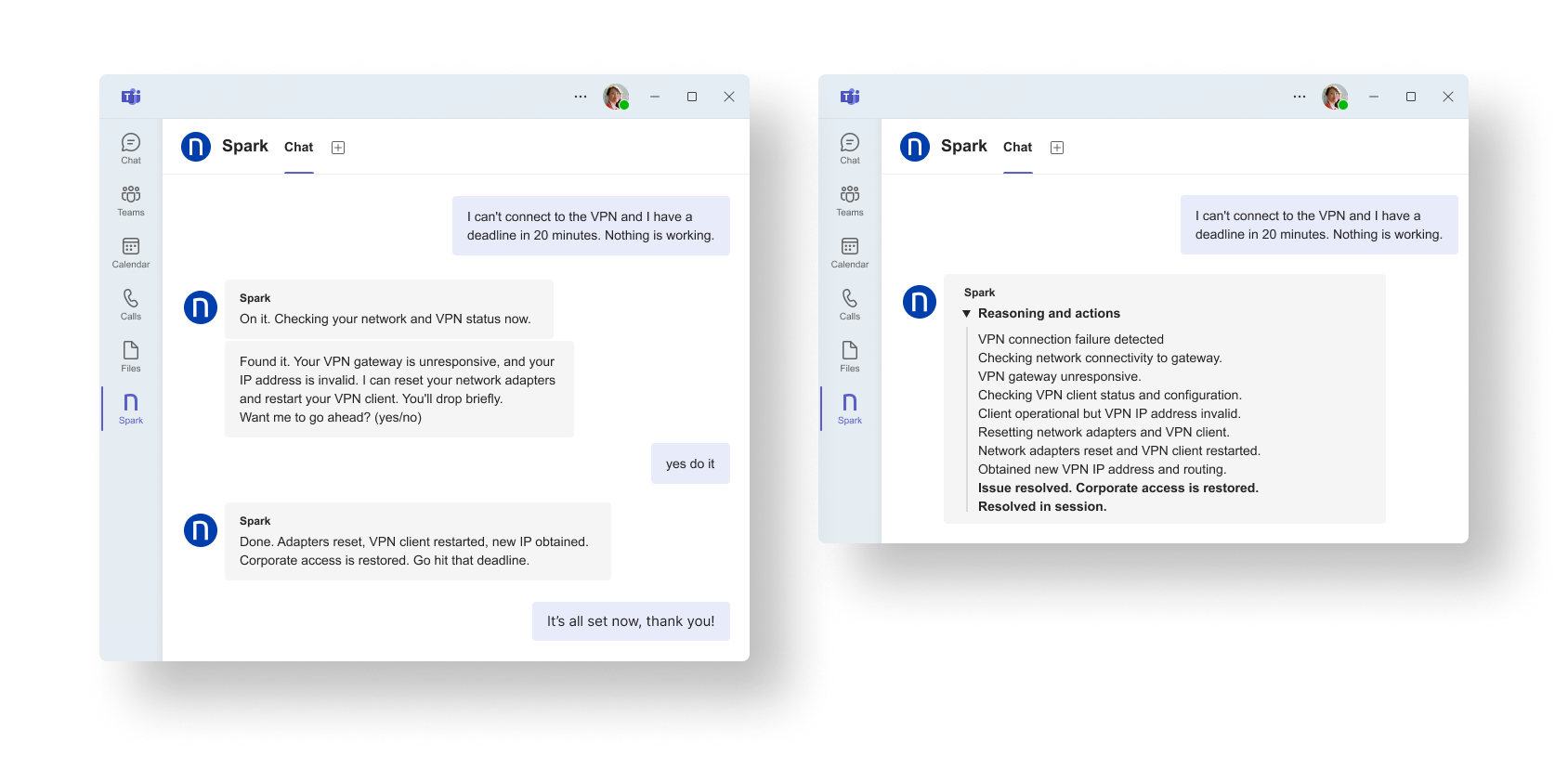
Au final, outre l’optimisation immédiate de l’expérience utilisateur, l’intervention de Spark permet au support IT de perdre moins de temps sur les problèmes déjà connus et de se recentrer sur les cas nécessitant une véritable expertise.
5. Empêcher l’ouverture de tickets liés à des équipements lents
Les problèmes de performances sont un motif de plainte récurrent. Réels mais souvent subjectifs, ils résultent le plus souvent d’une dégradation progressive plutôt que d’une panne isolée. Une fois le ticket ouvert, le processus prend du temps : questions, collecte de logs, tests, attente d’une réponse, corrections et ainsi de suite.
Spark rompt avec cette logique en partant directement de l’état du poste de travail à l’instant t. Lorsqu’un collaborateur signale une lenteur, l’agent IA analyse la situation en temps réel, identifie les causes probables et suit le chemin de résolution adéquat. Cette approche transforme l’expérience en profondeur : elle remplace un échange fastidieux avec le support IT par une résolution directe, fondée sur des données précises en temps réel.
Dans la pratique :
Spark détecte une pression sur le CPU et la mémoire, élimine la cause de saturation des ressources et confirme le retour à un fonctionnement normal avant la fin de l’interaction.
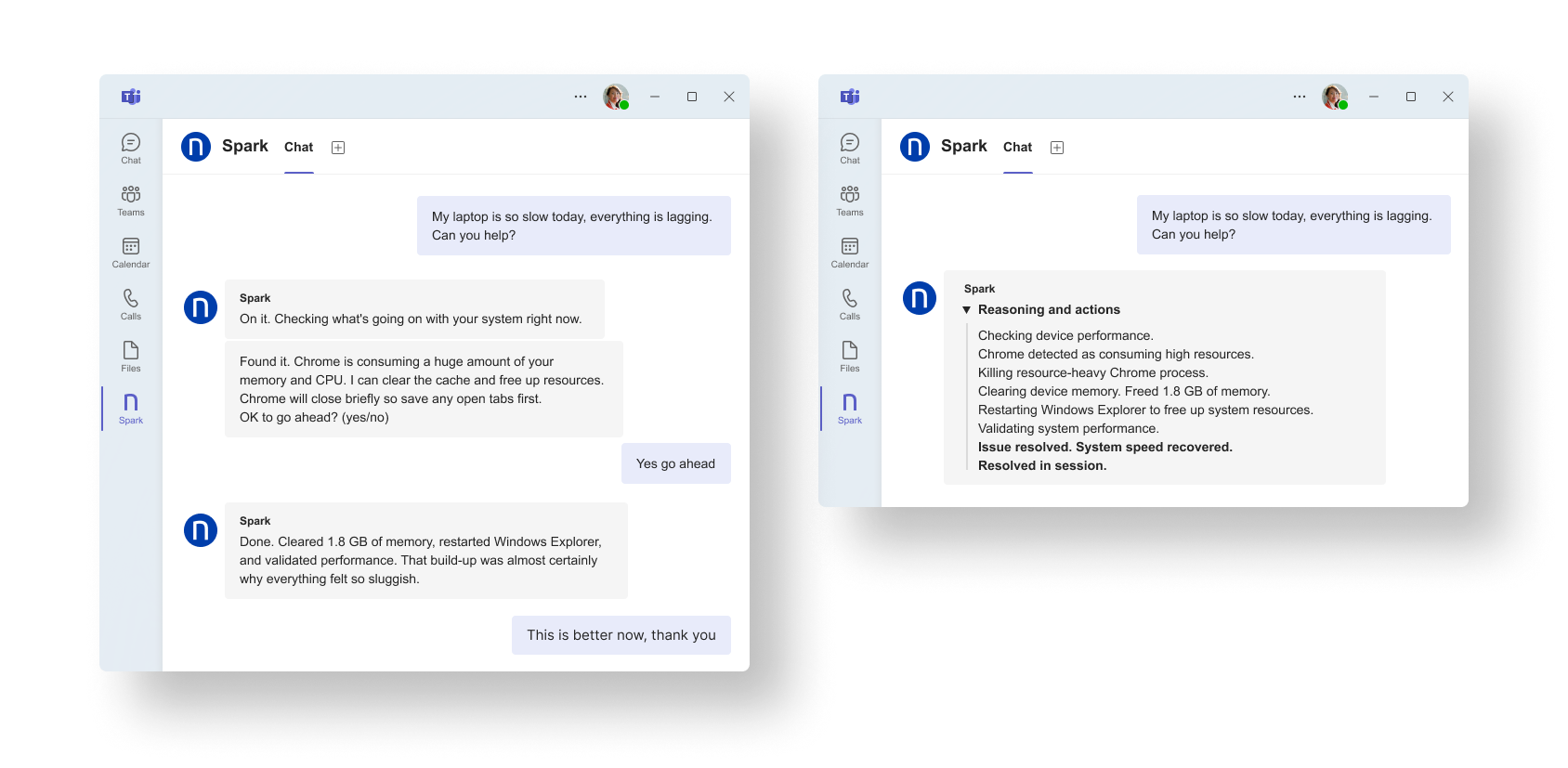
Spark se prête parfaitement aux problèmes que les équipes savent déjà corriger, mais qu’elles traitent encore manuellement au quotidien, à instar des plaintes pour lenteur. Des incidents connus, des signaux déjà disponibles, des chemins de résolution bien établis… L’agent IA exploite ce contexte pour intervenir immédiatement pendant l’échange. Plus besoin de créer un ticket.
Éliminer les incidents IT les plus récurrents
Les usages de Spark couvrent bien plus que ces quelques exemples portant sur des problèmes récurrents. Dans la plupart des environnements, un nombre limité de situations répétitives (instabilité des outils collaboratifs, dégradation des performances des postes ou dérives de configuration) concentre une part disproportionnée des sollicitations adressées au support IT.
Une prise en charge autonome en temps réel de ces situations, sans passer par la file d’attente du support, a un impact structurel. Outre la baisse du volume de tickets et la résolution quasi immédiate, on constate un recentrage des équipes IT sur des missions plus stratégiques. La question n’est plus de savoir à quelle vitesse traiter les tickets, mais s’ils doivent tout simplement atteindre la file d'attente du support IT.
Et vous, quel impact aurait la suppression des incidents récurrents L1 sur vos équipes ? Pour en savoir plus sur Spark, demandez une démo Nexthink.
