
Pioneering DEX Agents and Benchmarks

At Nexthink, our focus is Digital Employee Experience (DEX), it’s all we do, and all we aim to be the very best at. Today, we have a unique opportunity to deliver the world’s most advanced DEX models and agents, fine-tuned and trained specifically on real DEX use cases from our thousands of users.
This matters because, in our vision, most IT operations will eventually be fully automated by AI and technology. Establishing a benchmark for how autonomously and insightfully these systems can operate is therefore critical to build useful and reliable AI agents.
DEX challenges require not only strong foundational AI capabilities but also access to rich customer data that provides the right context, going beyond RAG approach that rely on generic, standardized datasets. So, the key question becomes: how do we evaluate their performance and improvement?
Introducing Benchmarks for DEX agents
Our first step in benchmarking DEX agents is to build an extensive dataset of challenges, a curated collection of 100 advanced questions that only the most sophisticated IT departments can solve today.
Each question represents a complex scenario or problem that a top-tier DEX professional could tackle with enough time, expertise, and access to the right data. These aren’t simple FAQs, but deep-dive queries designed to probe every facet of digital experience management.
Examples include pinpointing the root cause of widespread device crashes, identifying patterns in software performance degradation, or uncovering opportunities to improve remote work connectivity.
Question | Requested |
Is VDI offering a better experience than physical | Extract insights regarding what are the key |
Is my ERP the best one in the industry in terms of | Provide a comparison with other ERP tools from |
What OS has the highest satisfaction rate? | * Offer information about how to do sentiment * Summarize what people are talking about regarding * Extract insights in terms of differences between |
Access the comprehensive list of DEX Agent Benchmark questions.
Evaluating Benchmarks for DEX agents
Building great benchmark questions is only part of the challenge. The real challenge is figuring out how to score the answers. Traditional text similarity metrics like ROUGE or BLEU fall short for DEX evaluation because they reward word matching rather than true semantic correctness. An AI agent could deliver the perfect troubleshooting steps using entirely different phrasing from the reference answer, and still be penalized.
A more effective approach is LLM-as-a-judge: using an LLM to evaluate responses. This method is scalable, explainable, and closely approximates human judgment, which is otherwise costly to obtain. Research shows that LLM-as-a-judge achieves over 80% agreement with human evaluators; matching the agreement rate between humans themselves.
This is the method we used to evaluate three different agents: Nexthink Assist, Assist 2.0, and Assist 2.5. We assessed them on multiple dimensions: accuracy, depth, and usefulness.
Our AI evaluator looks beyond correctness, considering key contextual factors: Did the assistant fully address the core issue? Did it provide actionable next steps or just a generic answer? Did it guide the IT team toward further investigation or relevant platform data? By capturing these nuances, we get a holistic view of performance. An answer that’s technically correct but lacks insight might score moderately, while a truly expert-level response - correct, comprehensive, and actionable - earns top marks.
Let’s look at the results over multiple versions of our DEX Agent, Assist.
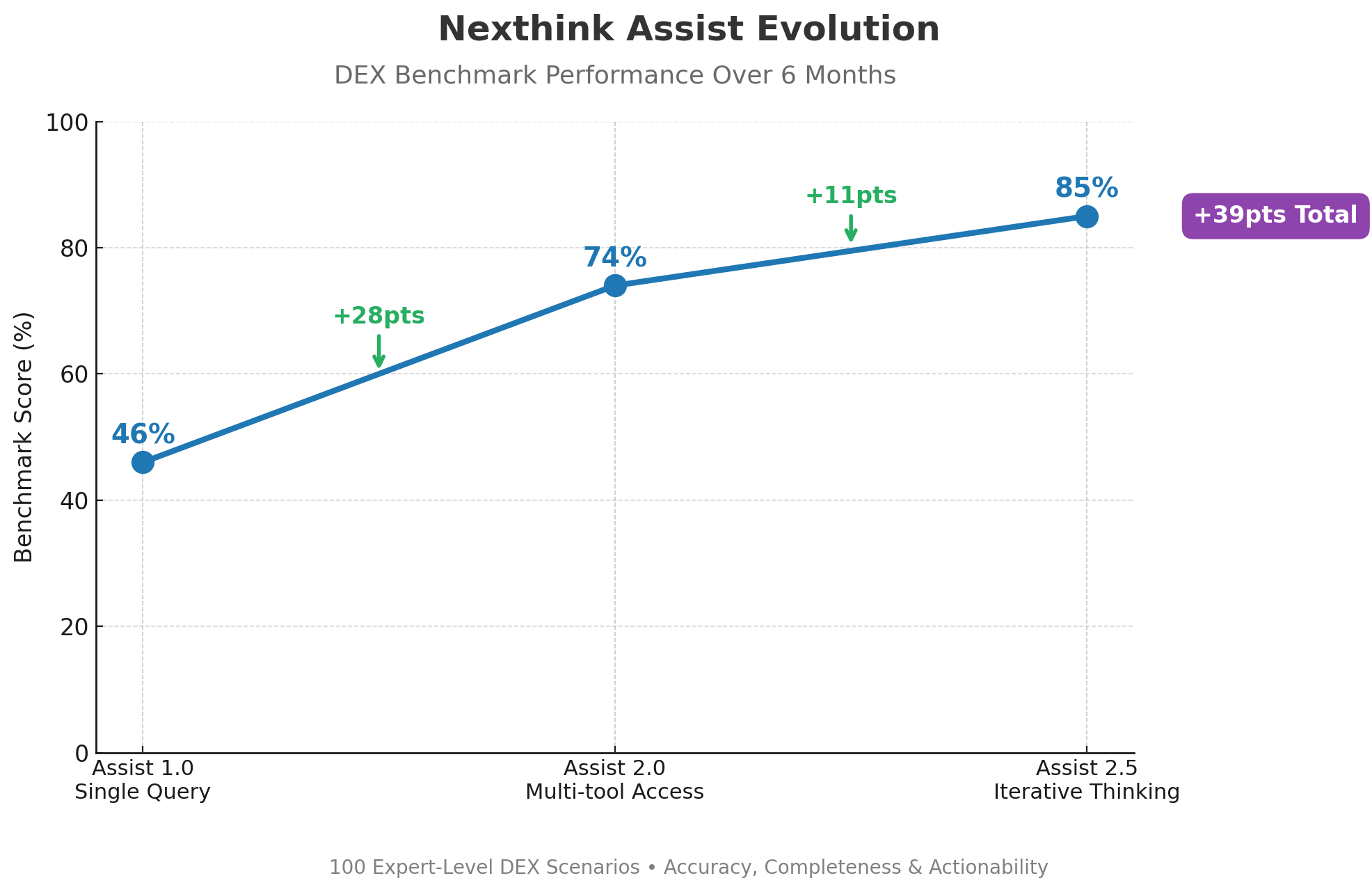
This chart tracked Nexthink Assist’s evolution over six months of development. The initial version (V1) could generate single database queries based on user questions, scoring 46% on our 100-question benchmark.
Assist 2.0 represented a major leap, expanding capabilities to access multiple tools - including NQL queries, dashboards, documentation, and Engage campaigns, which it could use once before summarizing its findings. This broader toolset boosted performance to 74%.
The introduction of iterative thinking in Assist 2.5 delivered the most dramatic improvement. Instead of making a single tool call, Assist could now iterate: running queries, analyzing outputs, and digging deeper with additional tool calls as needed. This agentic workflow pushed benchmark scores to 85%, setting a new high-water mark for DEX agent performance.
Example: Investigating System Crashes
One benchmark question asks: “What is the most common cause of system crashes in the organization?”
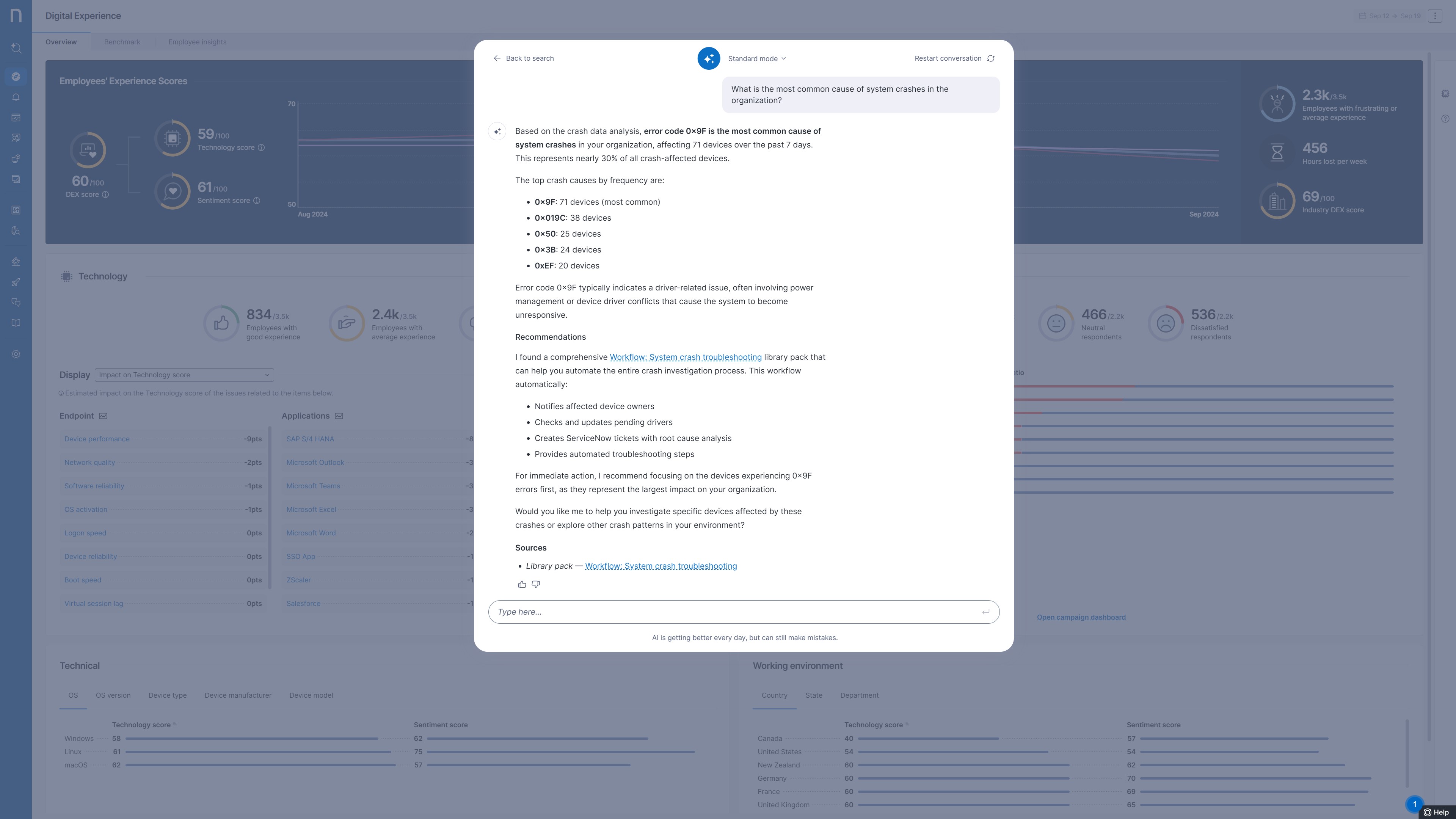
Identifying the correct cause earns only 67% of the points. The remaining 33% test practical problem solving and actionability: Did Assist redirect the user to a relevant dashboard for additional context? Did it propose a clear, data-driven action plan to remediate the issue using DEX tools and IT best practices? Did it surface any extra troubleshooting insights (like noticing that crashes spike after a particular update)?
This multi-faceted scoring approach ensures that Nexthink Assist doesn’t just retrieve data but also provides actionable insights to the IT team, acting as a true DEX assistant.
Check out the latest version of Nexthink Assist and see how it can solve your DEX challenges today.
