
Teaching AI to Speak Nexthink Query Language: Lessons from Nexthink Assist

In today's fast-paced IT environments, managing the Digital Employee Experience (DEX) shouldn't require mastering query languages or wading through endless data. IT teams need immediate answers, not more complexity. That’s why we have built Nexthink Assist, our AI-powered virtual assistant in Nexthink Infinity. By leveraging the power of Generative AI (GenAI) and Large Language Models (LLMs), Assist transforms the way organizations manage their DEX.
Nexthink Assist offers a range of powerful features, from answering product-related questions to generating advanced Engage campaigns (surveys) through a simple conversation with the user.
In this blog post, we’ll focus on just one to start with: its ability to understand plain English questions and automatically convert them into precise Nexthink Query Language (NQL) queries. This capability isn't just convenient—it's transformative. Our system proficiency in query generation and data retrieval means that every question returns relevant, meaningful data that IT leaders can act on immediately. No specialized query knowledge required.
In this post, we will take you behind the scenes and share the lessons learned from building an LLM-based system at scale that transforms natural language into actionable queries.
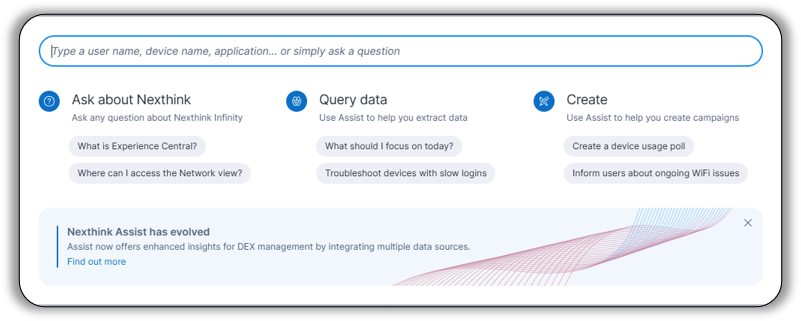
Natural language as the ultimate interface
Every powerful observability platform needs a robust query language at its core. For Nexthink Infinity, that foundation is NQL —a specialized language we designed to unlock the full potential of our platform's data. Whether users are monitoring DEX score evolution or analyzing call quality, NQL enables them to run investigations, build custom dashboards, and create targeted alerts.
Under the hood, Nexthink data platform transforms NQL queries into highly optimized SQL queries for our databases, handling the complexity so our users don't have to. At the same time, we recognize that even a domain-specific language such as NQL can be a barrier for many users, particularly those with less technical backgrounds.
That's where Nexthink Assist comes in. By bridging the gap between natural language and NQL, Assist democratizes access to Nexthink insights. Users can now simply ask questions in plain language and get the answers they need—no query syntax required. It's part of our ongoing commitment to simplifying our product and making powerful insights accessible to everyone.
From language to queries: AI's evolution
Parsing natural language queries into a structured query language is a long-standing and high-impact research topic in Natural Language Processing (NLP) and database community. It can be seen as a specialized instance of Machine Translation (MT): both tasks involve sequence-to-sequence transformation, where a sequence of words in one language is mapped to another. However, unlike conventional MT between human languages, this transformation requires additional considerations due to the formal constraints and logical structure of the target language.
Early approaches relied on rule-based systems and template matching followed by probabilistic models and semantic parsing using formal grammar. With the rise of deep learning, sequence-to-sequence models with Long Short-Term Memory (LSTM) and attention mechanisms improved performance, but still fall short of human-level performance with none achieving over 80% execution accuracy on the Spider dataset (Yu et al. 2018).
Recent breakthroughs came with the transformer architecture, leading to large-scale LLMs (e.g., BERT, T5, Codex, GPTs) that leverage pretraining and structured decoding for improved generalization in complex query generation. State-of-the-art (SOTA) text-to-SQL models have advanced to a point where they outperform average users in generating SQL queries from natural language inputs. However, they still fall short of expert-level performance, particularly in handling hard queries and nuanced questions. For instance, on the BIRD-SQL benchmark—a dataset comprising over 12,751 unique question-SQL pairs across 95 large databases—human experts achieve an execution accuracy of approximately 92.96%. In contrast, the leading model attains an execution accuracy of 75.63% (February 25).
While NQL is simpler than SQL, building an NQL query from a natural language question presents its own set of challenges (e.g., limited exposure during LLM pre-training) and opportunities (e.g., controlled data model). For example, SOTA text-to-SQL models rely on techniques like generating multiple candidates before selection, reasoning chains (e.g., Chain of Thoughts) and self-refinement, which enhance accuracy but increase response time. At Nexthink, we need near-instantaneous query generation to maintain a responsive user experience, which prevents us from currently implementing these more time-intensive but more accurate methods.
NQL building: step-by-step
Before automating generation, it’s essential to understand how a user would manually build an NQL query. At the core of NQL is its data model, it blends inventory data (objects like users, devices, and applications) with time-series events. Events can be discrete (e.g., logins, crashes) or continuous (e.g., memory usage). With 60 tables, each with 5-100 columns, and a partially dynamic schema—allowing customers to define custom attributes and metrics—query formulation is complex.

Figure 1 Given a question in natural language, constructing the associated NQL query follows a sequence of steps: table prediction, column selection, filtering, and compute.
The figure above shows the sequence of steps required to build an NQL query associated with a question expressed in natural language. As you can see, a solid understanding of NQL syntax and the underlying data model is crucial for building accurate queries. Each of these steps requires precise logic to ensure the generated query accurately reflects the user’s intent.
Mastering NQL: RAG to fine-tuning
In this section, we outline our journey from relying on foundational knowledge (zero-shot) to a fine-tuned model, starting with the evaluation framework that guided our progress.
Building a Reliable Evaluation Framework
Building an AI system requires a robust evaluation framework to quantify accuracy and detect regressions as the model evolves. To achieve this, we built a Golden Dataset—a benchmark that serves as our north star for measuring and improving model accuracy.
Each datapoint in the Golden Dataset pairs a user question with the ideal NQL query, forming our evaluation foundation. To ensure this benchmark truly reflects real-world usage, we curated a diverse set of anonymized Assist conversations, filtering out ambiguous user questions and manually refining imperfect ones. The result is a dataset that captures real-world query distributions, enabling Assist to generalize across our customers. Continuously expanding it ensures Assist adapts to evolving user behavior and maintains accuracy.
Now that we have a reference dataset, we need a robust evaluation method. Standard ML metrics like accuracy, precision, recall, F-score, or mean squared error address this need. However, evaluating natural language to query language conversion is more complex, as multiple correct queries exist for the same input. Valid queries may include extra columns, use different join or aggregation strategies, apply various aggregation methods, or vary in filtering and sorting while still producing the same result.
A common approach for evaluating text-to-query tasks is execution accuracy, which involves executing the generated queries and verifying that the results match expectations. We decided not to rely on this method because building and maintaining a dedicated evaluation database is time-consuming and requires ongoing updates to reflect evolving data structures. This challenge is further compounded by our use of a time-series database in Nexthink Infinity, where data is continuously aggregated and deleted, making it difficult to ensure long-term consistency in evaluations.
Moreover, execution accuracy alone does not fully capture the nuances of query generation. Two syntactically different queries may return the same results but differ in intent or structure. Conversely, execution-based evaluation does not explicitly verify whether the generated query truly aligns with the user’s intent—it only confirms that the output is correct for a given dataset. Instead, our approach is more demanding because we compare generated queries against expert-annotated reference queries. Over time, we experimented with several techniques, including:
- Component-wise evaluation, where we assess key elements of the query separately, such as selected tables, WHERE clauses, aggregations, and sorting. This helps pinpoint specific areas where errors may occur.
- Similarity scoring, which quantifies how closely a predicted query aligns with the reference query, accounting for minor variations while still ensuring correctness.
- LLM-as-a-judge, where an LLM decides whether two queries are functionally equivalent-even if they differ in structure.
By combining multiple metrics, we gain a more nuanced understanding of system performance, ensuring Assist remains accurate and aligned with NQL best practices.
Breaking down query generation
With an NQL data model exceeding 100,000 tokens, processing it in a single LLM context window is impractical. Instead, we break the task into 3 focused steps, mimicking how a human would build a query: (1) Identify the relevant subset of tables – reducing the search space from 80 tables to just 2-3, significantly reducing complexity (2) Determine the required columns – Selecting the most likely fields within the tables identified in step 1 and (3) Generate the query – Constructing the final NQL query.
This modular approach enables focused reasoning at every stage with targeted prompts (also called prompt chaining), faster development, and independent benchmarking of each step. However, decomposition increases response time and potential failure points—errors can propagate, impacting final query quality. Ensuring robustness at every stage is crucial for a high end-to-end reliability.
LLM foundational knowledge and structured output
We built our first prototype using LLM foundational knowledge (OpenAI GPT-3.5 and GPT-4) with carefully engineered prompts. This provided a good starting point, but we quickly realized that our model was generating syntactically incorrect queries.
The root cause lay in domain-specific languages (DSLs) like NQL: Although Nexthink is used by over 1,300 companies, NQL does not scale to the same extent as SQL, which benefits from a wider adoption and therefore publicly available training data. Consequently, during the pre-training phase, LLMs had limited exposure to NQL, making it difficult to generate accurate NQL queries.
To mitigate this, we restructured query generation. Instead of directly generating an NQL query, the model directly produces a JSON representation of query components, offering 3 key benefits:
1) We leverage the LLM’s strong exposure of SQL, to generate the correct query components.
2) We control and validate each part of the query before final assembly.
3) We deterministically build the query, reducing hallucinations or invalid syntax.
While this method significantly improved syntactic correctness, it exposed that generic LLMs lacked a deep understanding of our data model. This meant they often struggled to correctly map specific user questions to the right metrics, leading to irrelevant queries. To address this, we moved to Retrieval Augmented Generation (RAG), a technique that helps the LLM generate better answers by first searching for relevant information and then using that information to produce a more accurate and context-aware response.
Pushing the limit of RAG
RAG improves the generation accuracy by dynamically retrieving and incorporating domain-specific resources—NQL documentation, schema definitions, and validated NQL query examples—into the model prompt.
To build a large and high-quality dataset, we leveraged our internal workforce for data collection and labeling. Each annotator reviewed anonymized NQL queries, identifying and labeling the corresponding natural language questions they answered.
With RAG, we measured a 15% accuracy increase on our golden dataset. However, in our continuous effort to enhance query generation, we analyzed failure cases and uncovered the following key observations: First, in some situations, the model failed to reproduce exact example queries injected in the prompt, highlighting a generation issue rather than a retrieval problem. Second, as prompts grew larger, information dilution became a challenge—the model struggled to extract the relevant information in the prompt. Finally, we observed that small prompt variations led to significant differences in output.
This signaled that we were hitting the accuracy limits of RAG—context alone was insufficient for the model to internalize and generalize new NQL skills.
Fine-tuning: scaling accuracy and efficiency
LLM fine-tuning tailors a pre-trained model to a specific task by further training it on a smaller, domain-specific dataset. This enhances its performance for specialized applications while preserving general knowledge. It’s like training a new employee—they arrive with broad skills but need on-the-job training to grasp company-specific processes, terminology, and best practices.
After RAG, fine-tuning was the logical next step—but not a decision we took lightly. Yes, it means a significant upfront investment in development, specialized infrastructure, and longer iteration cycles. Unlike RAG, which allows for rapid experimentation with prompt engineering, fine-tuning requires a more methodical, resource-intensive approach and a deeper AI-engineering expertise.
The risk of overfitting or amplifying biases is real. However, the potential benefits are too great to ignore: fine-tuning reduces prompt size, mitigates information dilution while lowering latency and the cost per token. More importantly, it enables training on thousands of data points rather than just a handful retrieved at inference, allowing the model to develop a deeper understanding of NQL and business-specific context.
Fine-tuning eliminated the need to restrict the assistant’s scope, ensuring comprehensive support across our entire data model. Additionally, fine-tuning ingrains NQL best practices into the model’s weights, improving query generation, consistency, and predictability.
Our initial fine-tuning attempts with OpenAI’s GPT-3.5 and GPT-4o Mini yielded disappointing results: the models failed to adhere to NQL syntax, often hallucinating columns, operators, or invalid queries. The opaque nature of OpenAI’s fine-tuning process limited our ability to control the model evolution and refine the results.
We then turned to open-source models, which, despite adding complexity in managing GPU infrastructure for training and inference, delivered a significant leap in quality. We used the Amazon SageMaker platform and capitalized on recent advances in modern training techniques, such as Low Rank Adaptation (LoRa), Flash Attention, and distributed training to fine-tune a 7 billion parameters LLM in a cost efficient manner.
LoRa was key to our approach: it is an efficient fine-tuning technique that reduces computational and memory costs by modifying only a small subset of the model’s parameters. Instead of updating all weights in a massive model (more than 7 billion in our case), LoRa injects small, trainable low-rank matrices into specific layers while keeping the original pre-trained weights frozen. This enabled us to retain the general language proficiency of the base model while augmenting it with expertise in NQL generation.
Despite clear benefits, fine-tuning introduced operational challenges. Meticulous training data curation became essential as fine-tuning performance heavily depends on high-quality, representative datasets. Poorly annotated data or repeated patterns (e.g., outdated timestamps, dummy identifiers) could degrade model quality. Infrastructure management introduced new operational hurdles such as continuous GPU resource management and cost optimization, scaling based on real-time production load and minimizing inference latency while ensuring reliability.
Nevertheless, the improvements were substantial:
- 30% accuracy improvements
- 80% reduction in token usage
- Comprehensive data model support
With training iterations now costing less than $100, fine-tuning has unlocked a whole new level of potential for Assist’s query generation capabilities while reducing memory footprint and remaining cost-effective.
Looking to the Future
The journey of teaching AI to understand and generate NQL has been one of continuous learning and innovation. Our approach—from RAG to fine-tuning open-source models—has significantly improved accuracy (+30%) and efficiency (80% less tokens), ensuring Assist delivers better insights while keeping a responsive user experience.
Assist has transcended its origins as a query builder to become a true DEX analyst, empowering IT teams not only in troubleshooting but also in strategic initiatives such as cost optimization and IT sustainability improvements. With these improvements, Assist is transitioning into a true AI agent—capable of autonomously selecting the right tools for each question, reasoning through complex scenarios, iterating to refine its outputs and summarizing the finding in a clear actionable way.
Looking ahead, we envision Assist continuing this trajectory by incorporating more powerful fine-tuned LLMs, enhancing its reasoning capabilities, and expanding test-time compute—essentially giving Assist more 'thinking time' to brainstorm and generate higher-quality insights.
The future of AI-powered DEX is here, and Nexthink Assist is leading the way.
