
Comment pallier les failles de votre logiciel d'alertes IT traditionnel

Certes, il arrive que les tickets de support concernent un problème isolé. Mais bien plus souvent, ils ne sont que le symptôme d’un mal beaucoup plus profond touchant nombre de systèmes et d’utilisateurs. Du jour au lendemain, ce mal peut empirer et impacter la plupart des collaborateurs, avec pour conséquence une forte hausse du nombre d’appels au support. Résultat : une paralysie totale pour vos équipes, vos départements, vos business units, voire votre entreprise tout entière. Gaspillage de ressources, surveillance accrue de la direction, atteinte à la réputation professionnelle, risque de licenciement… ces situations d’urgence entraînent des réactions en chaîne pour les équipes IT et le support.
C’est précisément pour échapper à ces scénarios catastrophes qu’ils recourent à des logiciels d’alertes censés leur permettre d’anticiper les dysfonctionnements. Le problème, c’est que les solutions d’alertes traditionnelles s’avèrent inopérantes et n’améliorent en rien la situation.
Qu’est-ce qu’un logiciel d’alertes et pourquoi est-ce indispensable ?
Un système d’alertes informatique assure un suivi continu des serveurs, infrastructures, applications et autres afin de prévenir les équipes IT de toute situation critique. En cas de baisse des performances, ces outils sonnent l’alarme auprès des ingénieurs IT. Ces derniers sont doublement gagnants puisque non seulement ils n’ont plus besoin d’effectuer manuellement ce monitoring, mais ils peuvent également intervenir avant que la situation ne devienne irrécupérable.
Lacunes des logiciels d’alertes actuels
Avec l’adoption massive et définitive de modes de travail hybrides, les collaborateurs ne dépendent plus exclusivement des réseaux d’entreprise. Les applications et même les postes de travail migrent de plus en plus vers le cloud à mesure que les solutions SaaS et DaaS gagnent du terrain.
Tous ces facteurs contribuent à réduire la visibilité de votre équipe IT sur l’expérience numérique des utilisateurs. Dans ces conditions, difficile d’identifier, de diagnostiquer et de corriger les problèmes avant qu’ils ne provoquent un déferlement d’appels au support.
Malheureusement, les solutions et méthodologies existantes s’avèrent inefficaces, car elles se concentrent sur des silos technologiques qui génèrent des données inexploitables et dépourvues de tout contexte sur les impacts côté collaborateurs.
À titre d’exemple, les outils PCLM aident, certes, à configurer les systèmes d’exploitation, à implémenter des correctifs et à déployer des applications. Mais ils ne fournissent aucune information sur la performance d’une application métier critique et encore moins sur l’expérience et le ressenti utilisateur.
De même, les solutions de monitoring de l’infrastructure surveillent l’état opérationnel des serveurs ou des sites, ainsi que leur capacité à absorber la charge. En revanche, impossible de savoir quels collaborateurs n’ont pas pu se connecter à ces serveurs en raison d’un mauvais paramétrage de leur machine.
Quant aux technologies APM, elles passent le code applicatif au peigne fin, mais n’offrent aucune visibilité sur l’expérience complète des collaborateurs sur ces applications depuis leur machine ou navigateur.
Et quand bien même cet éventail d’outils rassemblerait toutes les données en un seul et même endroit, cela ne suffirait pas à l’équipe IT pour éviter le scénario catastrophe : un support inondé d’appels, provoquant l’immobilisation totale de l’activité.
Alertes informatiques : bienvenue dans une nouvelle ère
Pour être efficace, un système d’alertes doit communiquer des signaux faibles axés sur l’expérience numérique complète de chaque collaborateur, poste de travail, application, et ce, en continu et en temps réel.
C’est là que les fonctionnalités d’alerte en temps réel de Nexthink Infinity interviennent.
Nexthink Infinity offre une visibilité unifiée pour cerner les besoins des collaborateurs, les outils qu’ils utilisent et les problèmes qu’ils rencontrent. Réseaux, applications, environnements IT… tous les éléments sont corrélés et mis en contexte pour déterminer leur impact sur l’expérience numérique des collaborateurs. En d’autres termes : pour veiller à ce que les technologies répondent à leurs exigences.
Concentrez-vous sur l'essentiel
Des alertes intégrées et personnalisées permettent de suivre la performance de vos applications, machines et infrastructures les plus critiques. Vous voulez vérifier la réactivité d’applications SaaS clés pour vos métiers ? Ou encore comprendre pourquoi une application plante systématiquement pour certains collaborateurs ? Nexthink Infinity vous transmet les signaux faibles indispensables pour devancer le déferlement potentiel de tickets d’assistance.
Notifications intelligentes
Une fois les problèmes identifiés, l’étape suivante consiste à en informer les bonnes équipes. Nexthink Infinity notifie en temps réel les équipes IT des problèmes critiques. Pour ce faire, la plateforme s’intègre à des systèmes tiers, notamment les principaux outils ITSM, pour informer les équipes à tout moment, dans leurs propres outils et avec tout le contexte nécessaire.
Priorisez les réponses selon l'impact
Les problèmes qui importent vraiment ne sont pas ceux qui nuisent le plus gravement à l’infrastructure ou à des réseaux spécifiques, mais ceux qui impactent les collaborateurs et leur productivité. En centrant les analyses sur les données expérientielles à tous les niveaux de l’entreprise, vous pouvez déceler les problèmes cachés, identifier les dysfonctionnements qui impactent le plus grand nombre d’employés et enfin prioriser vos tâches de manière à accélérer la reprise d’activité.
Nexthink Infinity, c’est une plateforme centralisée qui permet de visualiser, de gérer et de hiérarchiser les problèmes d’expérience numérique les plus pressants pour les collaborateurs.
Gage de proactivité pour l’équipe IT, elle aide à cerner et à corriger les défaillances réelles. La preuve par l’exemple :
Cas d’usage – Mettre fin aux plantages d’un agent de sécurité
Après avoir configuré des alertes en temps réel pour un agent de sécurité important, un client américain du secteur financier apprend que l’agent s’est soudainement mis à planter.
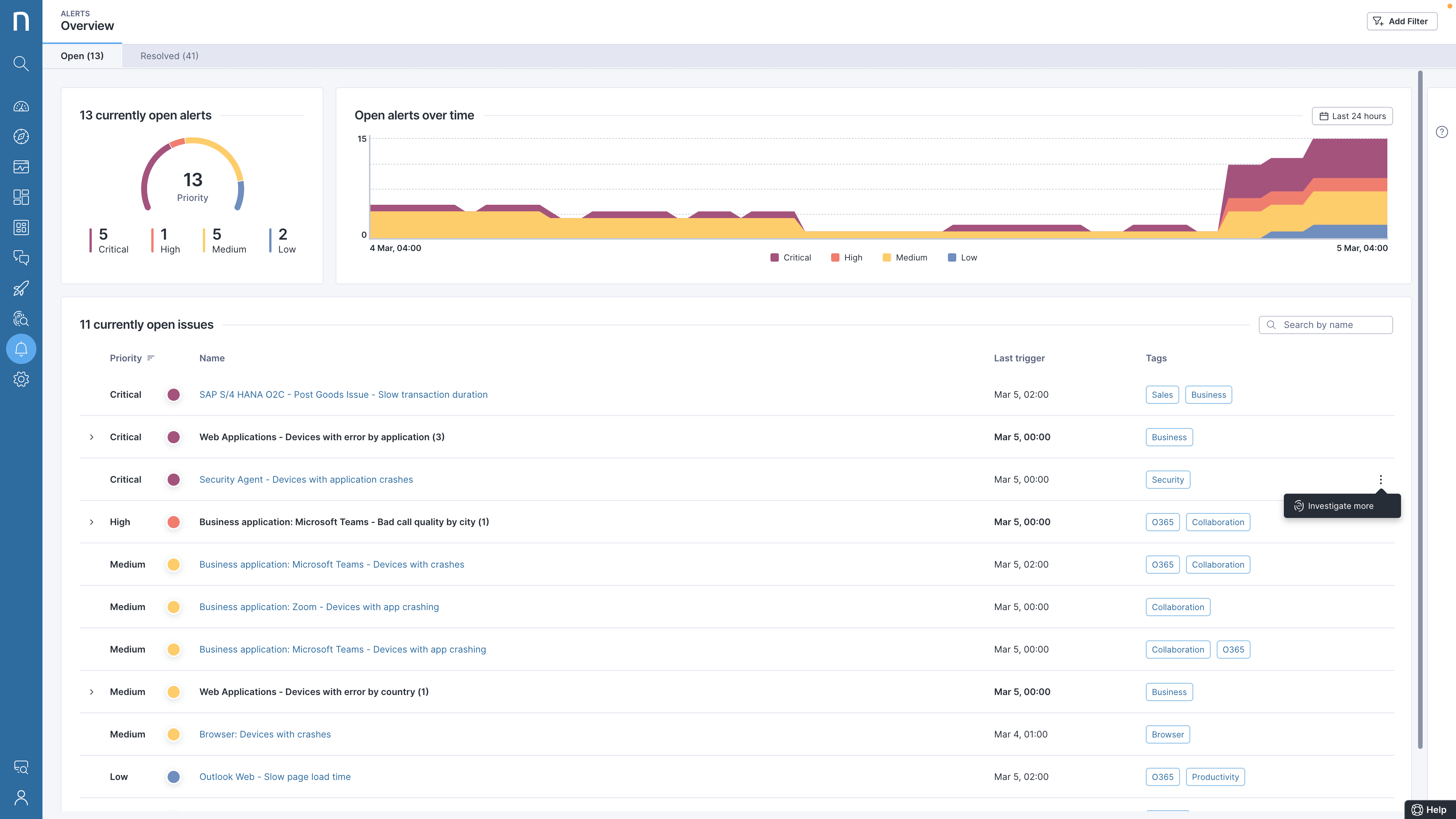
Après analyse, il s’avère que les pannes se produisent à un emplacement particulier et qu’elles sont liées à une version spécifique de l’application.
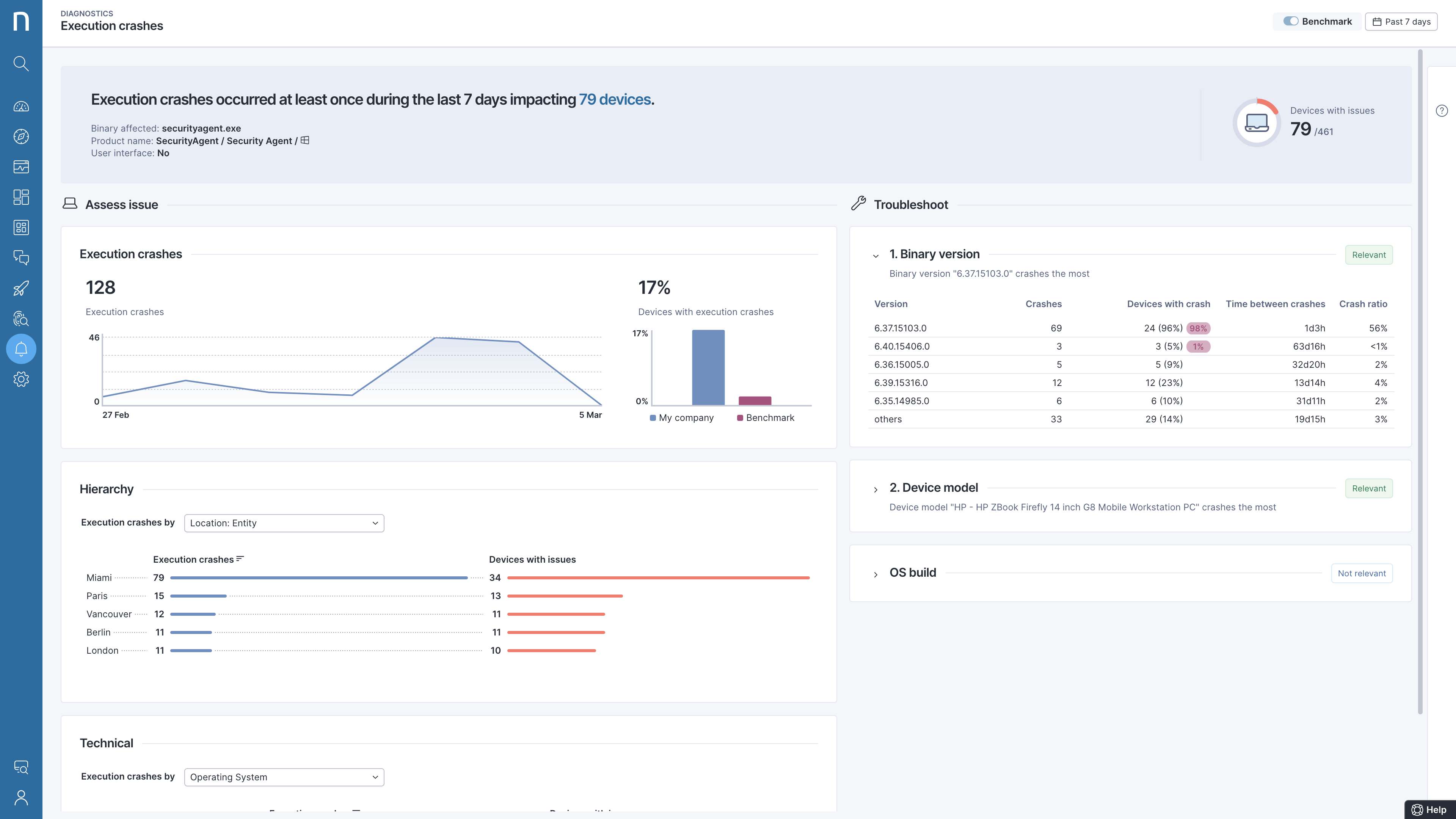
Une fois le problème détecté et toutes les machines impactées identifiées par Nexthink Infinity, un correctif est déployé en arrière-plan sans perturber les utilisateurs.
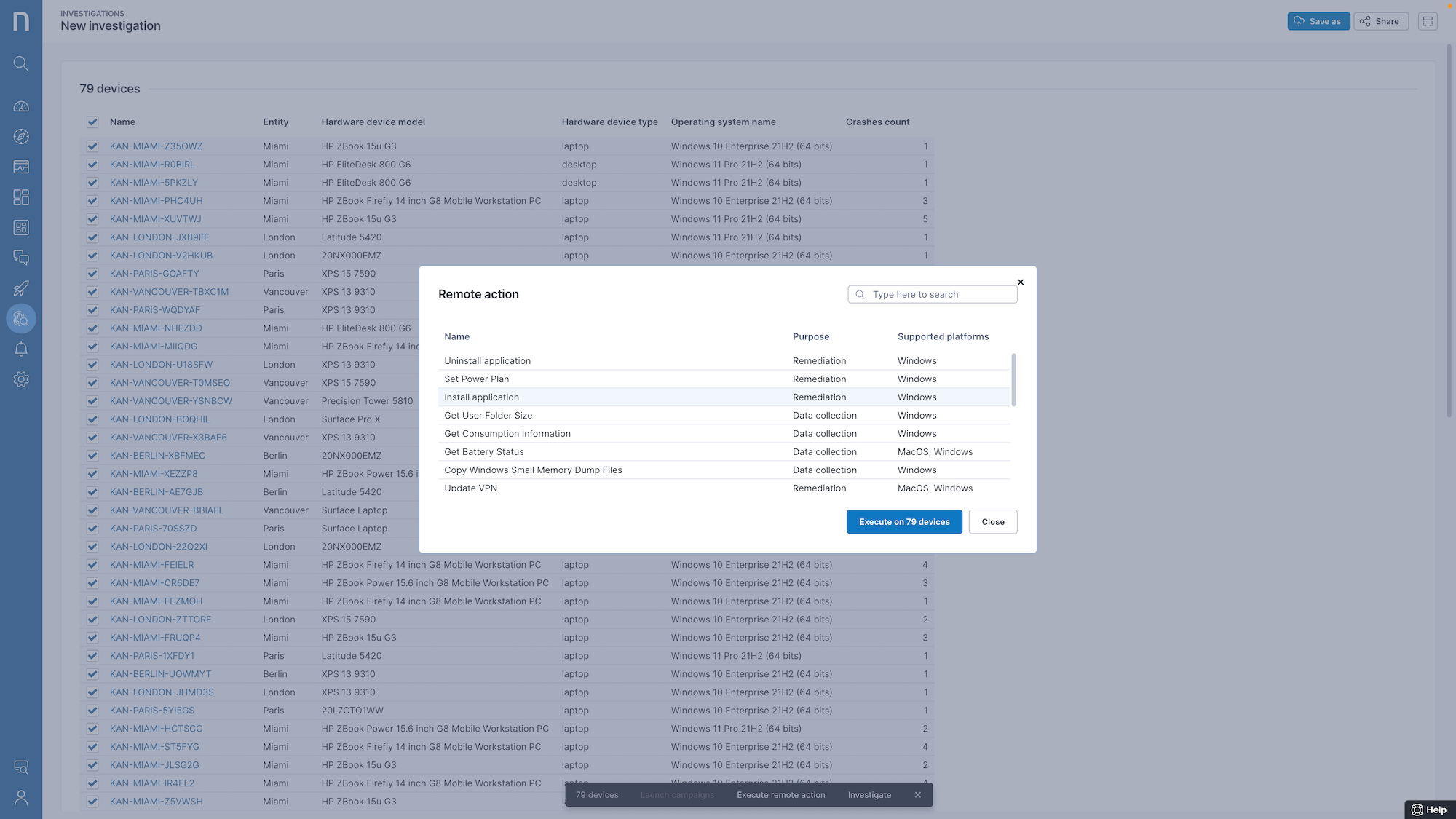
Mieux encore, l’équipe IT résout le problème avant même que le moindre collaborateur ne le signale : la catastrophe est évitée.
Pour ce client qui opère dans un secteur hautement réglementé, les solutions traditionnelles, axées sur l’infrastructure ou les réseaux, n’auraient pas permis d’identifier le problème. L’équipe IT en aurait découvert l’existence au moment où les collaborateurs impactés l’auraient signalé. Grâce aux fonctionnalités proactives de Nexthink, ce client a pu prévenir de potentiels problèmes de non-conformité sur les machines en question. Et en termes de délai, plus besoin d’une investigation de plusieurs jours pour identifier la cause et l’ampleur du dysfonctionnement. Ce cas client est le parfait exemple d’une approche de résolution centrée sur les collaborateurs.
Avec Nexthink, jouez la carte de la prévention des sinistres informatiques
À force de se reproduire, les petits couacs deviennent vite des dysfonctionnements majeurs. Or, il est impossible d’identifier et de prioriser les problèmes sans une vue d’ensemble en temps réel. Nexthink Infinity est conçu pour répondre à un enjeu majeur pour toutes les entreprises : cerner l’expérience numérique de chacun des collaborateurs, en continu et en temps réel, pour permettre aux professionnels IT d’identifier, de diagnostiquer et de résoudre les problèmes les plus nuisibles pour leur productivité.
En savoir plus sur Nexthink Infinity.
