
Adapting Legacy Systems to a Stream-Based Platform
In a perfect world, small pieces of software scale up and down with a high-performance message broker like a heart, pumping data in a controlled, efficient manner.
However, at some point, in every single system, an application starts pumping out large data requests, in a sporadic, uncontrollable manner. Because here, we are talking about the real world, right?
In this article, we will address the problem of adapting a legacy system to play with a stream-based platform.
The High-Level Idea
On one hand, we have a very modern and sophisticated stream-based platform. The whole design is meant to scale and be ready for incoming challenges in the form of new products, bringing the Digital Employee Experience to the next level, so we will be able to delight our customers.
On the other hand, we have the legacy system, a very sophisticated and powerful piece of engineering, that is still in use and providing value to your customers and your company.
This legacy system has, at least, one last duty to accomplish: feed important data to the new and modern platform, described in the first paragraph.
The Stream-Based Platform
Powered by AWS, here we could find a microservices world, floating into a Kubernetes cluster, communicating together through a Kafka cluster, and everything under the premise of high availability and scalability.
All the flow has very well design, every single data structure and communication has been carefully implemented, with no bottlenecks, to obtain the high-performance that is required for providing the best Digital Employee Experience.
The Legacy System
In this case, we are talking about a very well-designed monolith. All the features included, make sense on the idea of a monolith.
This legacy system has many purposes. One of them is to collect information that must be analyzed and processed by an external (to the monolith) system. The monolith will send HTTP requests to that external system with all the information it could accumulate in a certain time frame. One shot with everything.
It expects a response when the data is analyzed. If only part of that data is analyzed, the legacy system will send back the pending part.
The Problem
Transferring important data from the legacy system to the stream-based platform. The legacy system and the stream-based platform were meant for two different purposes, at different eras, and, at this point, the transfer of data between them is not 100% compatible.
On one hand, the legacy system is used to transfer as much as information it could accumulate in a certain period of time. On the other hand, the stream-based platform is meant to transfer the information in a de-coupled way, at its own pace, with no stress among the microservices.
What happens when you have to move a body request of 90MB through a queue?
Your stream-based platform will encounter a BIG problem, because most probably your applications are not able to digest 90MB in one single request.
And, what happens when this same system receives thousands of requests like that in a short time frame?
Your stream-based platform will encounter a BIG problem and you will have to act FAST, because you will have to solve the same problem described before, but extremely fast.
Divide And Conquer Solution
Divide And Conquer has been, historically, a very good solution for many problems, also in software and system engineering.
Referring to the problem mentioned in the previous section, we could try to chop those big requests, on the entry point (a load-balanced microservice with multiple Pods) of your stream-based platform. If your queue system only supports 1MB for each message you produce, you should have to split that 90MB into chunks of 1MB (max) to transmit just one message through the stream-based platform.
Why?
So that the microservices who care about that data, will take it, and use it for their purposes.
Maybe, splitting the body request is not enough. Maybe that 90MB body request has linked information, which you cannot process in a separate manner. Then, you have to split, transfer, and join the chunks back in the proper order. This means much more processing, hence, the load on your entry point (microservice) will be increased.
Moreover, what if the body request is not just a JSON blob, but a Protobuf blob?
When you de-serialize a 90MB Protobuf body into a data structure managed by a microservice, you will end up with a big, and probably unexpected, punch on the memory heap. This means that the load on your entry point (microservice) will be increased, again.
Increasing the processes to be done, plus the heavy load to perform during the processing on the entry point, just for being able to enqueue the data, could end up in a situation in which the stream-based platform itself becomes a bottleneck.
Sponge mode solution
As we mentioned in the previous section (The Problem) the legacy system and the stream-based platform are not compatible. Their designs are not compatible, they were meant for different eras (one for the 90s the other for the 2020s).
When you throw a big stone into a small pool, the situation is going to be like white water, with many and big waves, even you might find that the water in the pool gets out, because the big stone will replace the space. Pure physics. When you throw a big stone into a very big lake, you will experiment that only some small and occasional waves appeared, the stone is covered completely by the water.
If we replace the words “throw” by “processing”, “stone” by “body request” and “pool/lake” by “data storage or queue” … I think you get the point.
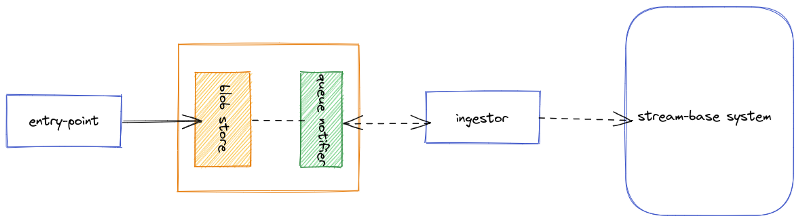
On the entry point, instead of trying to go directly to produce the information on the stream-based platform, let’s store it first into a blob storage. From there, the stream-based platform will notice about information, through a queue, to be digested and do what it’s supposed to do: take the data and process it at its own pace.
Cloud providers, such as AWS, offer well-documented and powerful Blob Storage systems, from which you can store your big body requests (90MB in our scenario), through an SDK available for many programming languages.
This also allows you to include metadata on the blog you upload to storage. Thanks to this metadata, or tags, the stream-based platform can perform much more sophisticated processing, and not just “download and process.”
Final thoughts
Even if you have a very sophisticated and powerful stream-based solution, this is not a silver bullet solution when you have to mix and mingle with legacy systems. Engineering has to solve the puzzle and find out the best approach for each use case.
Message broker systems, such as Kafka, Pulsar, and others, will not fit all use cases, and you have to adapt the periphery of your system and architecture to process that information appropriately before reaching the heart of your platform.
Related posts:
- Your MS Teams Rollout Needs Specific Help—Not General Guidance
- What Your IT Chatbot Can Look Like Running on Full Power
- 8 Websites Every End-User Computing Professional Needs to be Visiting Daily
- Paul Hardy (ServiceNow): The Changing Role of IT
