
How One Company’s IT Service Desk Used Automation to Reduce Incident Tickets

How a Northern-European car manufacturer dramatically reduced incoming tickets related to low disk space using 4 key automations.
Incident tickets are an unavoidable, routine aspect of working in IT. But failing to identify and solve the root cause of the issue behind repeated tickets will cause unresolved tickets to pile up, creating a huge disruption for IT and employees.
In most organizations, Service Desk teams wait until an employee submits a ticket to begin the incident management process – but by then, it is already too late. While the Service Desk works to resolve that individual ticket, the root issue is impacting several other employees, repeating over an over. More and more employees report the issue, the tickets continue to get resolved one at a time. But the tickets are coming in too fast for the Service Desk to keep up with, and now that organization is identified as a “top call driver.”
In most organizations, a “top call driver” is a nightmare scenario: time is wasted, tickets are escalated, employees are frustrated and L1 agents are burnt out as the entire Service Desk team tries to solve an issue that could have been avoided easily.
Proactive IT: Visibility and Automation
This is why IT needs to be proactive and leverage preemptive analytics.
A proactive IT strategy allows IT and Service Desk teams to detect and resolve the root cause of incidents before too many tickets are submitted. Or, better yet, before these issues can impact the digital experience of too many employees.
We already know that proactive IT starts with pre-incident visibility, as discussed here.
But, being aware of an issue is one thing. Being able to fix it quickly and prevent it from impacting more employees is another. This is where automation becomes a core component of proactive IT. And it’s exactly what a Northern-European car manufacturer did when they were faced with mounting piles of unresolved tickets.
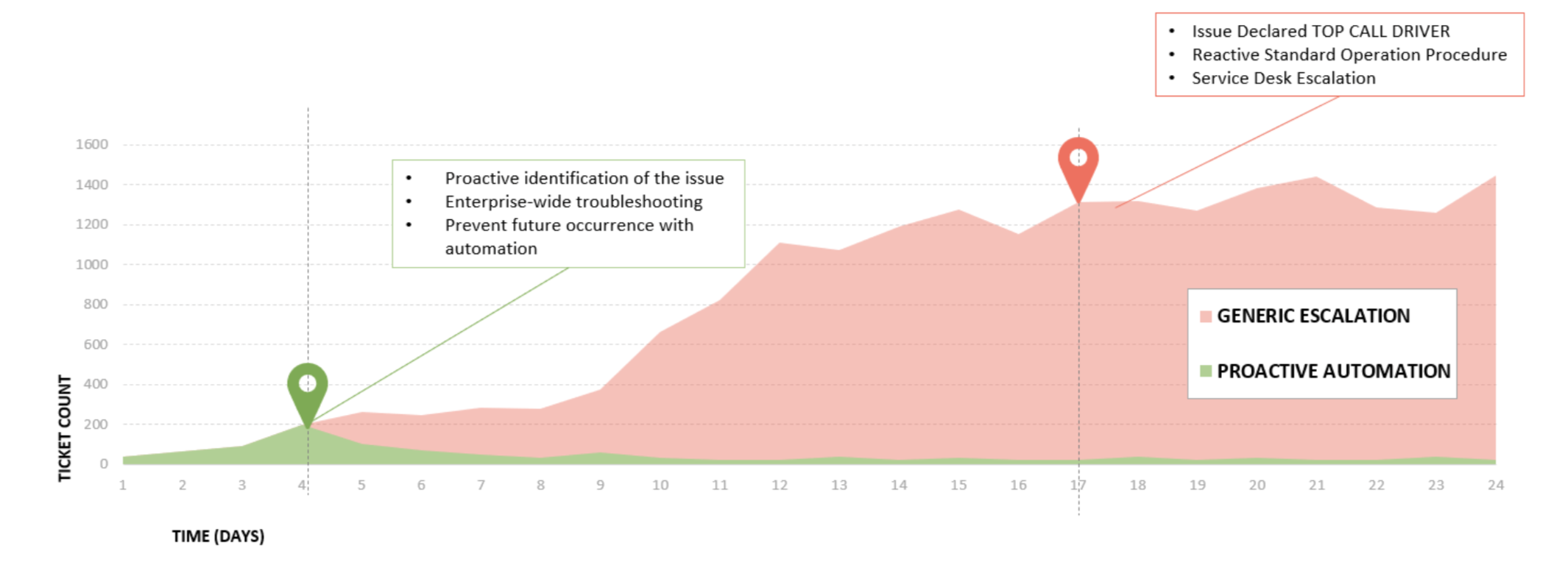
Red: Incidents are only resolved once an impacted employee has submitted a ticket causing the incident to become a top call driver
Green: Proactive automation is applied at the incident’s nascent stage to prevent it from escalating into a nightmare scenario
From reactive to proactive
Like many organizations today, this Northern-European car manufacturer realized that although they had invested a large amount in their Service Desk, employees continued to submit tickets. Their Service Desk team was continusouly resolving similar issues and the infamous nightmare scenario of “top call driver” was a reality.
This was one of their main reasons for implementing Nexthink as a key IT solution – proactive visibility and automation. They wanted to reduce the number of IT incident tickets coming in, and get ahead of the next “top call driver” nightmare before it happened.
Very quickly, the manufacturer gained the proactive visibility they needed to identify the root cause of their high ticket count. And more importantly, they saw how to resolve it quickly and effectively.
Reducing IT incident tickets with a 4-part automation strategy
One of their top call drivers had been “slow PC” with tickets continuously coming in from employees complaining about their laptop feeling slow or dragging. Every time an employee submitted an issue, an L1 agent would open the ticket and contact the employee to perform individualized troubleshooting – nothing too complex, but time-consuming nonetheless.
After deciding to become more proactive in their IT processes, a quick Nexthink drill down from their Experience Optimization dashboard confirmed “slow PCs” as the main source of frustration and, more specifically, that these slow PC issues were clearly related to devices running out of disk space.
To prevent this issue from recurring and reaching the Service Desk, IT implemented 4 quick and efficient automations:
1. Targeted, Contextual Engagement and Automated Fix
As a first step, the Service Desk team fixed the issue for every single user in the organization with low disk space. Because they could not perform a deep disk clean without employee approval, they leveraged Nexthink Engage to send a targeted engagement and single-click fix feature.
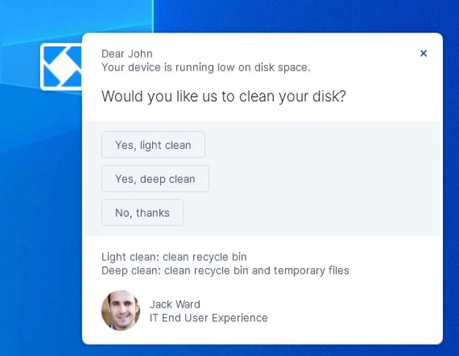
IT set a threshold of an 80% used disk space so that any employees above this percentage would receive a timely pop-up notification to inform them of the issue and recommend performing either a disk clean or deep-clean. A single click from the employee triggered an automated remote action to clean their disk on the spot. No IT-Employee communication or ticket submission required.
The Service Desk initially sent this campaign to resolve all the open tickets. But as a proactive step, they also set up a recurring campaign to send to any employees reaching the 20% free space threshold in the future.
2. ServiceNow Self-Service Portal Integration
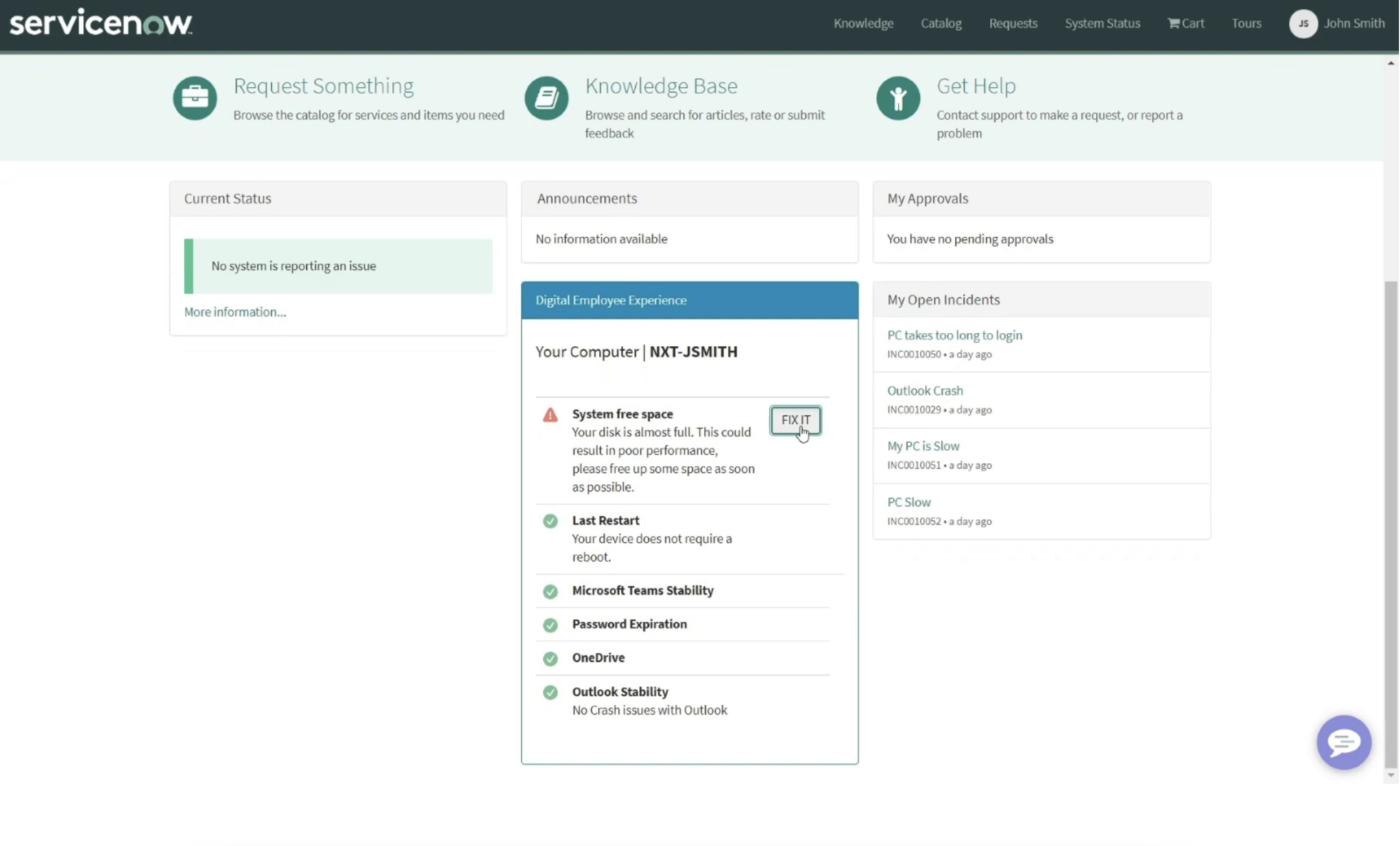
The next step was to give employees the means to resolve the issue themselves before ever having to submit a ticket. They did this by integrating the same disk clean remote action into their ServiceNow Self-Service Portal.
Any employees with low disk space on their devices (20% remaining) who visited the portal would be presented with a warning and a single-click fix to immediately remediate the issue – without IT interaction.
3. Chatbot Enrichment
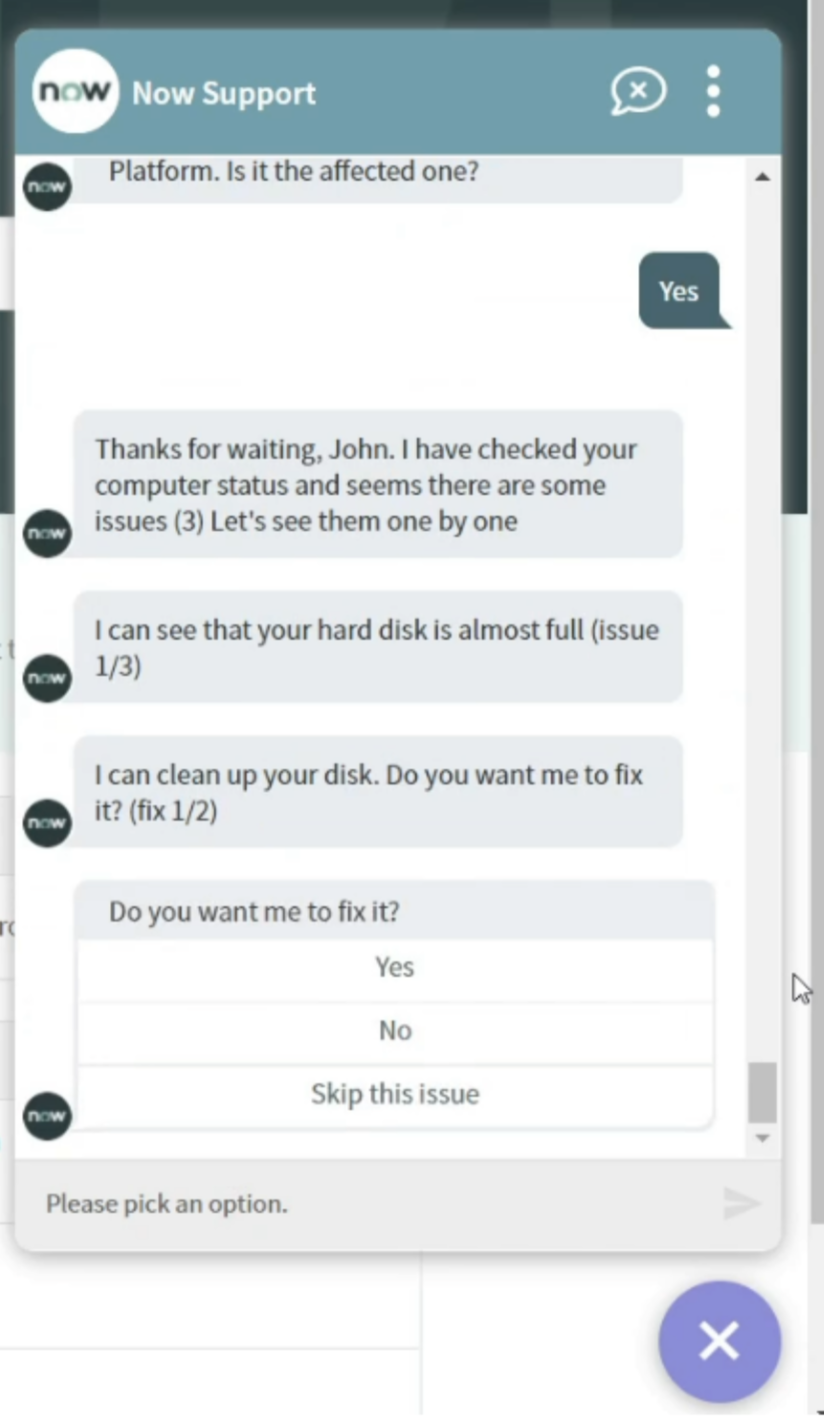
After the self service portal integration, the IT team turned their attention to the company’s recently deployed chatbot. Since the company had included a strong focus on self-help enablement in the chatbot strategy, IT also added this disk cleaning solution to their virtual agent.
Nexthink’s chatbot integration allowed the IT team to offer much faster and smarter chatbot responses leveraging key Nexthink data. The chatbot could prompt a disk clean single click remote action: employees asking the chatbot about slow pc related issues would get prompted with the same disk single-click remote action, directly accessible as a single click fix straight from the chatbot.
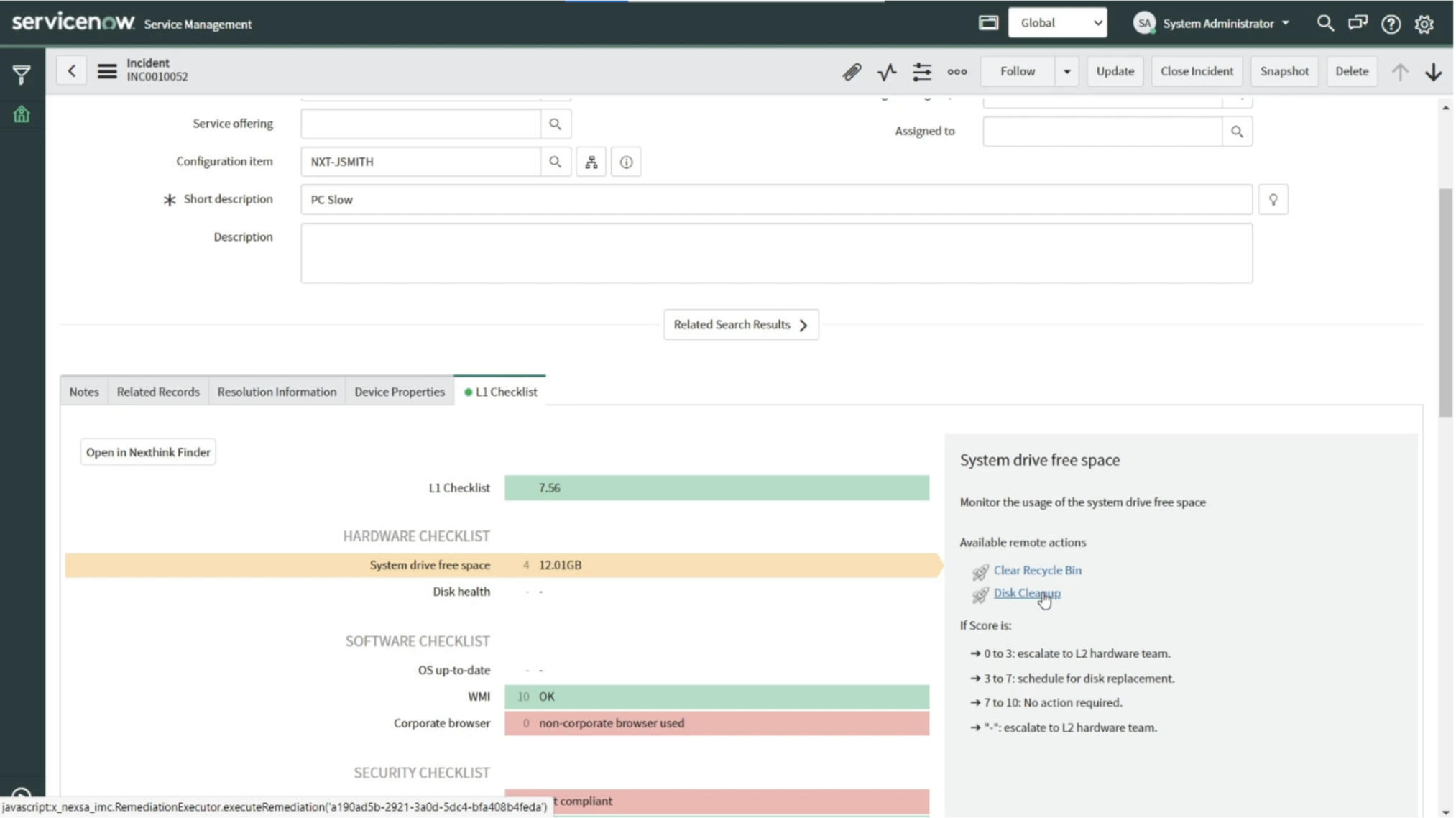
4. Single-Click Fix in L1 Checklist in ITSM solution
And, finally, in the event that tickets did come through, the Service Desk team integrated the disk clean remote action as a single click fix into L1 agents’ L1 checklist, integrated directly into their preferred ITSM tool (ServiceNow for this specific manufacturing company).
This dramatically simplified the L1 agents’ troubleshooting and accelerated their time to resolution by immediately detecting if low disk space was the issue and triggering the remote action and engagement feature, if necessary.
And that’s just one!
By making these fixes instant and accessible to employees, the IT team dramatically reduced their ticket count related to slow PC and low disk space to near 0. And if a ticket did arise – L1 could confidently resolve it within seconds.
Soon one of the most common IT issues was no issue at all.
And that’s just one issue! The company is now applying this method across a wide range of other common incidents to seriously reduce inbound tickets and, ultimately, better allocate the service desk’s time and resources.
Watch the full demo here:
Related posts:
- 5 Ways to Reduce the IT Incident Backlog Before Your Team Gets Crushed
- How to Get Ahead of Recurring IT Tickets (Use Case)
- 3 Ways to Enhance Your Service Desk With Real-Time Experience Data
- Proactive IT 101: Learn How to Build a Proactive Service Desk
