
How Nexthink Helps You See and Diagnose Issues at Scale

Digital Employee Experience is vital to attract and keep the best employees. A solid DEX strategy also increases employee productivity and motivation, a selling point for business leadership across the board.
Yet, IT teams have less and less ability to control the factors that make up the digital employee experience. Although IT still own the devices, most of the network and applications are managed by third-party vendors. How can IT see, diagnose and fix issues when they can't see the underlying data?
Identifying the Data to Measure DEX
To solve IT issues, you need the data. But how do you know which data is the right data? Any common IT issue, such as device slowness, can be triggered by a wide range of causes: hardware performance, network congestion, Wi-Fi issues, or application defects, to name a few. Because of this complexity, most monitoring and DEX tools put a strong emphasis on data granularity and breadth of data. The approach being “let’s give IT all the data that might contribute to an IT issue, with the highest granularity possible, and let them figure things out”.
Although this approach might work in some cases, when IT teams have strong technical experts dedicated to this type of troubleshooting, it is simply not scalable:
- It is often a device by device approach.
- It requires deep knowledge of hardware, network and application performance and metrics.
- It is time consuming, tactical and not predictable in terms of outcomes.
Leveraging cutting-edge capabilities to analyze large data sets at scale, Nexthink takes a more proactive and scalable approach to see, diagnose and fix application issues. Thanks to the amount of endpoints covered by its technology, Nexthink has the capability to detect when third-party vendors go wrong and hold them accountable. Our customers can leverage these insights to know if the issue is on their side, or the vendor side, and use that data in conversations with vendors to help ensure the issue is resolved.
Using Nexthink Data to Drive Vendor Conversations
Nexthink can detect when a version of an application does not work well with, for instance, a specific OS version, and assess the impact in terms of experience and number of devices impacted.
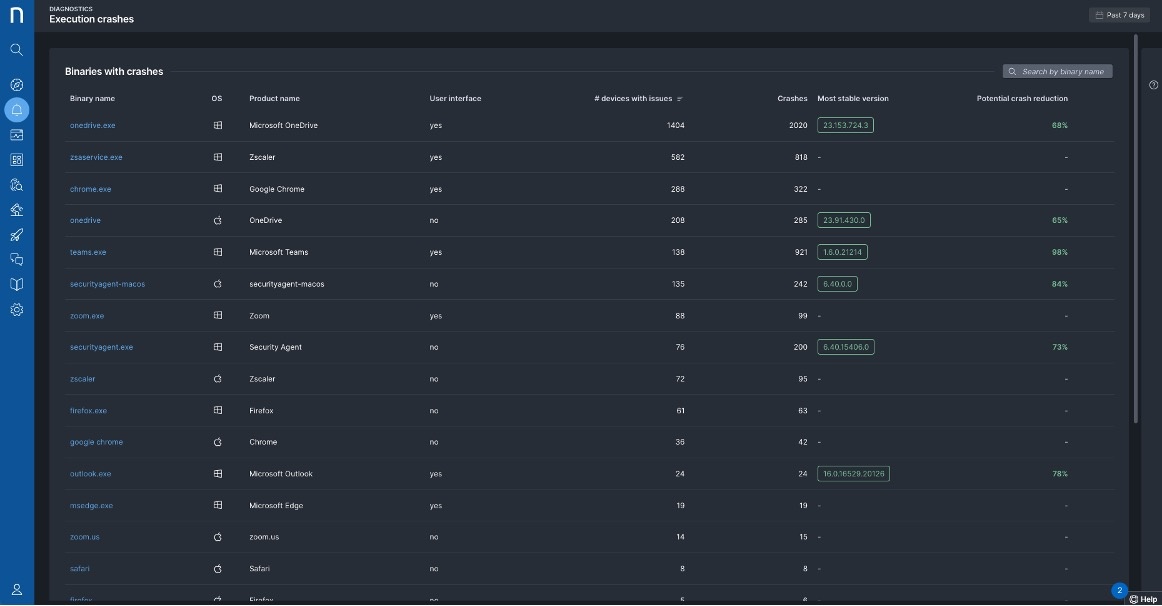
Above, Nexthink recommends upgrading unstable binary versions. Below, a security agent is identified as causing crashes.
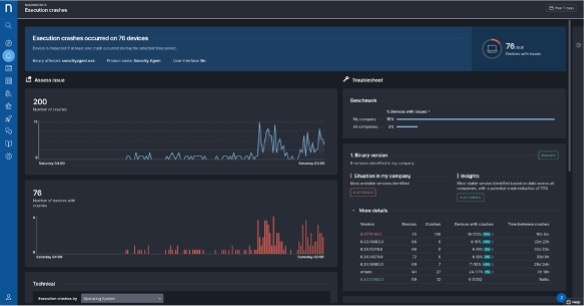
With this approach, organizations can:
- Fix most issues at scale, avoiding tactical device by device troubleshooting.
- Hold vendors accountable, being able to prove that several other organizations are also impacted and therefore the issue is on the vendor side.
All this with minimal technical knowledge required, as Nexthink identifies the issue, the impact and the root cause with no configuration and analysis required by the IT team.
This allows IT to become even more proactive, as Nexthink can guide IT's decision whether or not to upgrade to a new version before an organization starts the change process.
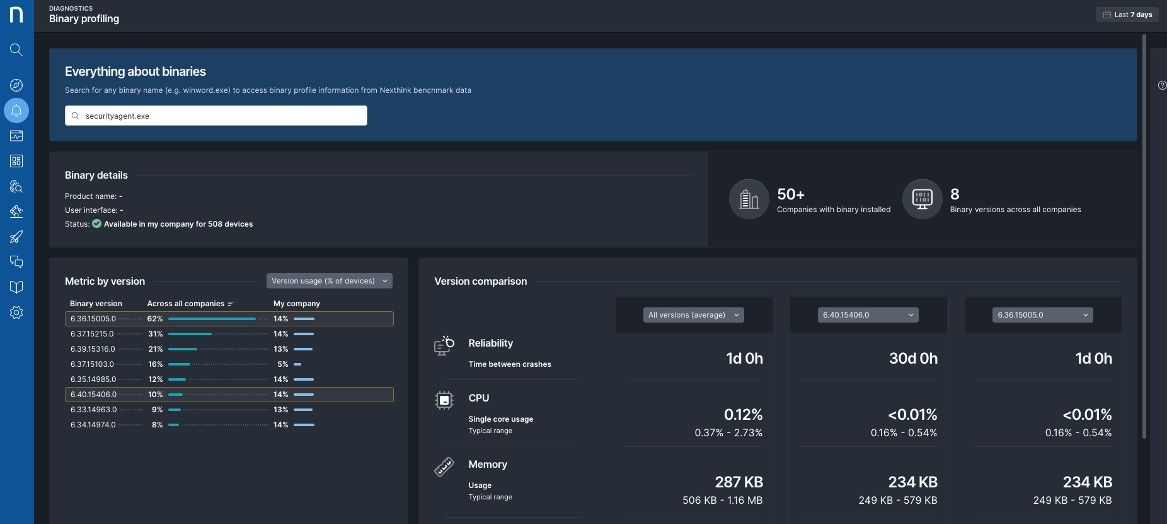
Above, anonymous customer data from millions of endpoints allows comparisons of binary versions.
Nexthink's approach to data-driven decision making has already helped several organizations uncover issues such as:
- A new DLP agent version causing high CPU and crashes, severely degrading the experience of employees.
- A collaboration tool causing high CPU during calls, impacting tens of thousands of employees working in a call center and therefore customers of this organization.
- A security agent taking 2GB of memory on several endpoints, heavily impacting these devices.
In all these scenarios, a ticket was opened with the vendor, who acknowledged and fixed the issue. When organizations can bring data illustrating the root cause of applications issues, vendors are more likely to listen and take action.
