
3 Steps to Reduce IT Tickets Without Impacting End User Satisfaction and Productivity
Recently, a top consulting firm’s VP, of IT Operations, managing 80K endpoints asked: “What shall we do to Drive down the Service Desk cost by 30%?” This doesn’t come as a surprise. In fact, we’ve been hearing this question from many IT teams lately, across all industries. EUC managers know that reducing Service Desk costs will directly impact employee satisfaction and result in an increase in escalations. This needs a more logical approach, and technology has to play a major role in achieving this objective. Nexthink has proven time and time again that enterprise reduces their IT tickets by, on average, 45% with the following approach:
Step 1: Monitor and Maintain the Workplace Desired State
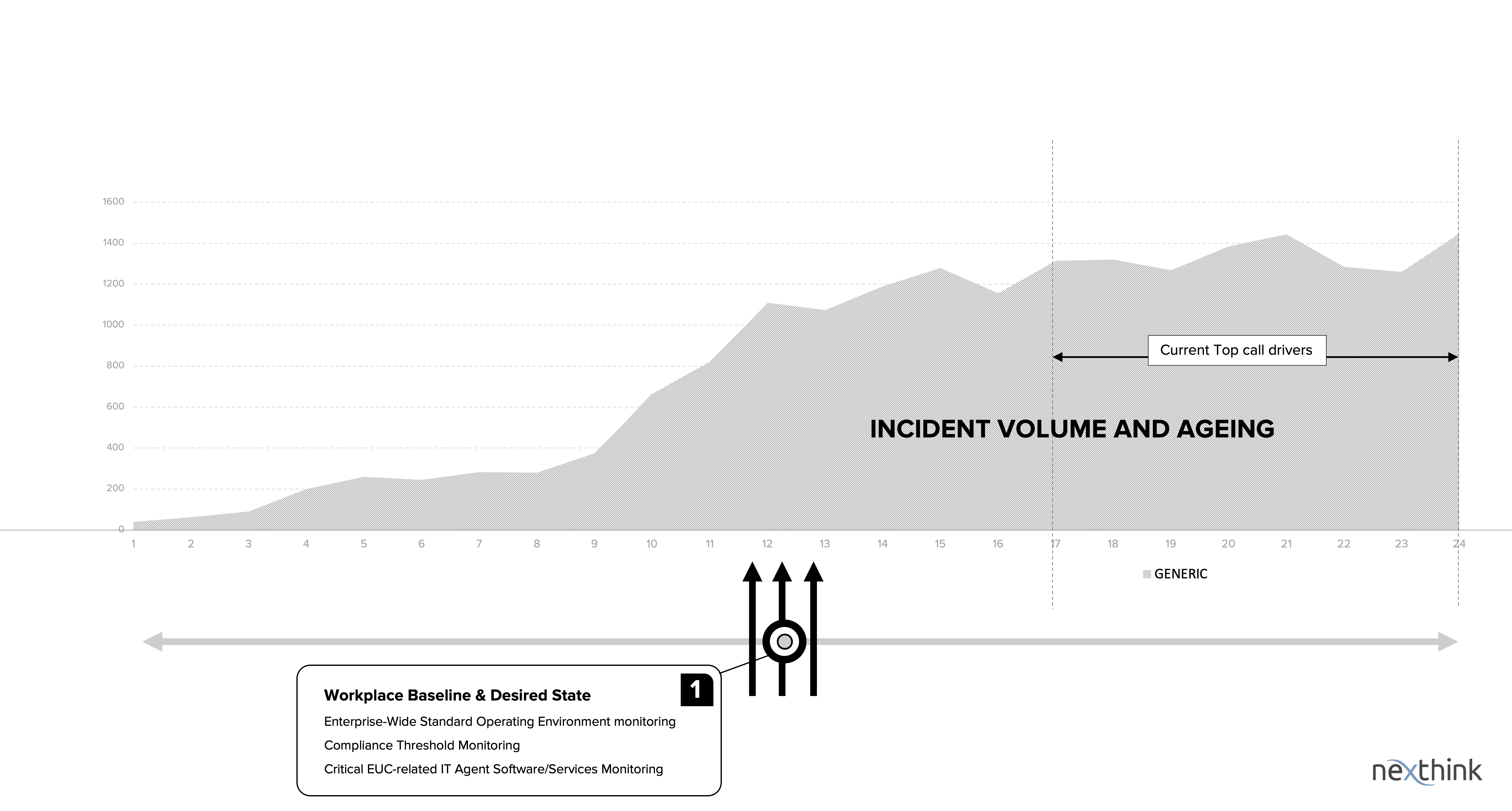
Eliminate Top Call Drivers
The CTO of a large Managed Service Provider with more than 300K endpoints explains,
“Every endpoint in the organization consists of a carefully curated and tested set of applications and software. To keep these devices functioning error-free and provide the best throughput, we put certain critical agent software in the device. This agent software is meant to do a dedicated and focused activity on the device such as Virus Protection, Manage Configurations and Versions, Manage Authentication, Manage Encryptions etc. Now if we treat these agents as the core housekeepers of the Device, responsible for their own housekeeping activities, and if all of them do their job right then, it is very rare for those devices to have major IT issues.”
he also explains with a great metaphor…
“…It is like we keeping our house clean and protected first within and then focus on the boundary aspects. If we have issues within the house, it is easy for any external elements to easily get in and make the issue much worse and more dangerous.”
User Incidents are Boundary issues and they need to be addressed. But for us to efficiently approach this, we need to first address the issues within. A process to Baseline the IT assets and enforce the desired state. The IT team could first on priority focus on the core components of the device;
- are they as per the Standard Operating Environment [SOE] as per organization policy?
- are there any exceptions from the expected standard and steps to enforce the desired state?
- are those critical agents meant for specific activities performing as expected?
If the Helpdesk and the IT teams together find out ways and means to address the above questions more efficiently, it is positive that the quantum leap they would gain in incident reduction will be dramatic and very significant.
Nexthink has observed more than 40% of the Mundane and recurring User initiated incidents can be “eliminated” with this one initiative of “Workplace Baseline & Desired State”.
Nexthink Infinity provides a single view that helps you understand what employees are using, what they need, and what incidents they are facing – across the entire enterprise, all the time. All employees, all computing environments, all applications, and all networks and set in the context of how these all relate to delivering a digital experience – that is, how well the technology is working from the employee’s perspective.
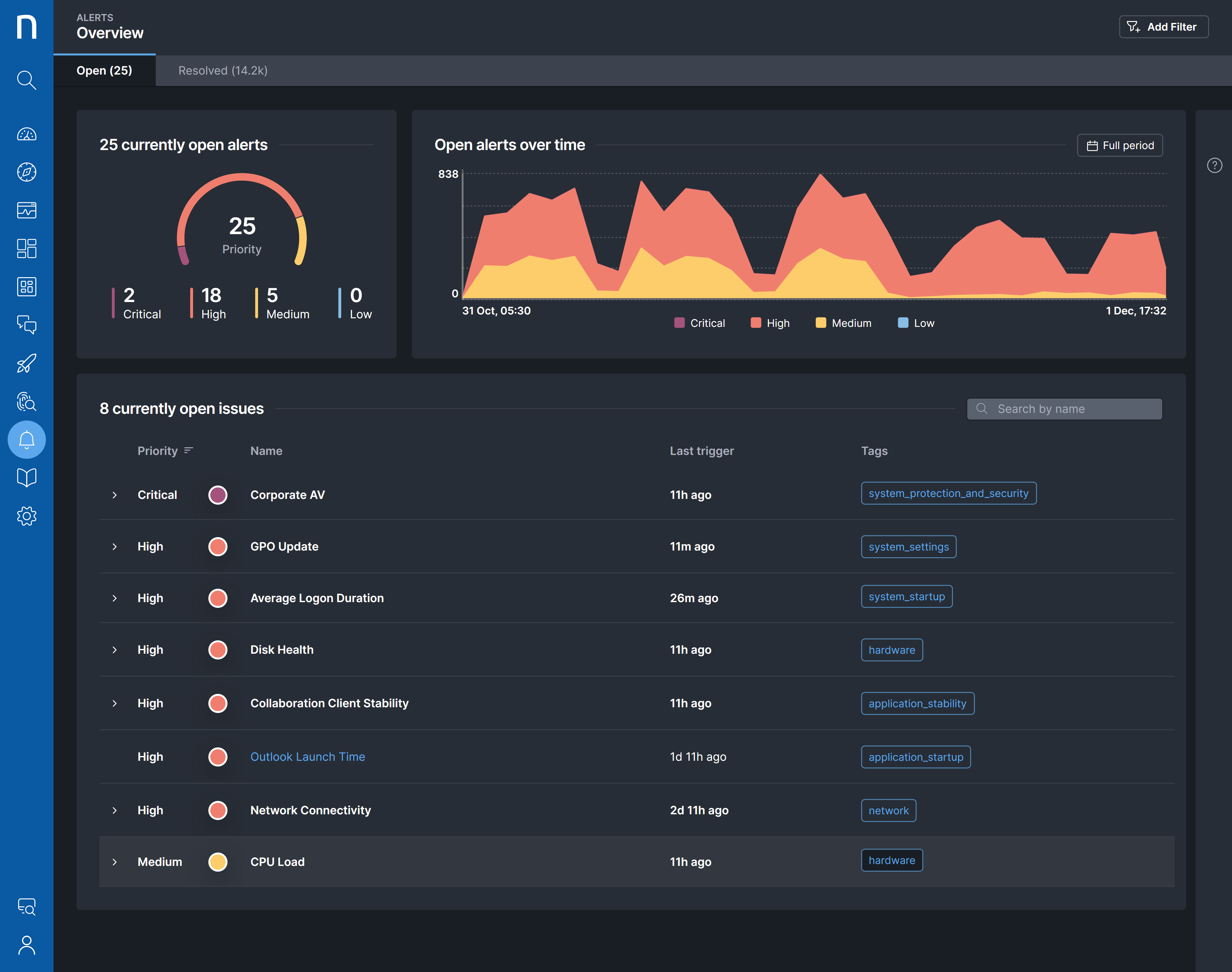
Built-in and custom alerts enable you to monitor the Desired State of the Workplace, Compliance with the Standard Operating Environment, and most mission-critical software agents. Infinity delivers the early warning needed to ensure you and your teams are always ahead of potential ticket storms
Nexthink Library Pack: The Manage Configuration Drift pack allows you to track, detect and remediate devices in your landscape that have “drifted” from a defined compliance baseline.
Step 2: Shift Focus from Ticket Volume to Ticket Age
Eliminate Top Call Drivers
Focusing on Reducing the age of every ticket logged rather than focusing on the volume of the top call tickets will turn the Service Desk super-efficient. The more we reduce the age of every ticket, the more the question of “top Call Drivers” will never arise. Question is, is it possible to reduce the age of the tickets? We need an early issue identifying technology in place to proactively prevent any issues from becoming top call drivers.
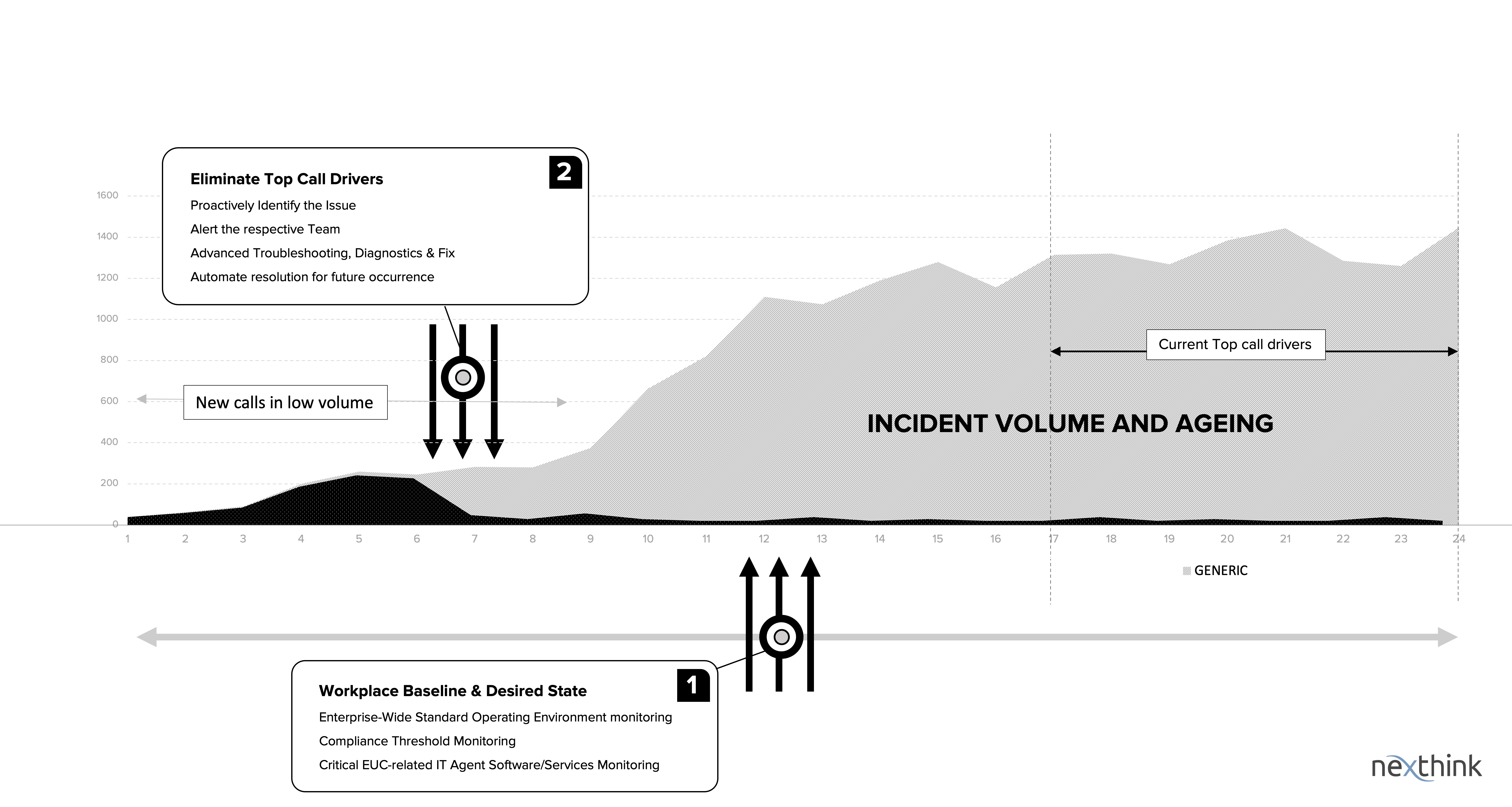
Proactive incident reduction requires visibility into the earlier stages of an incident lifecycle. In other words, your IT team needs to be able to monitor in real-time the appearance of potential issues – issues that have yet to make a major impact on employees’ digital experience but might do so if you don’t address them.
95% of the user-logged incidents can be addressed and resolved before they become top call drivers.
With the ability to proactively identify low-volume issues early on, you can then:
- Alert the affected users and provide preventative support.
- Perform advanced troubleshooting to identify a solution before the problem takes its full effect.
- Automate the resolution of the issue to prevent it from reoccurring – or impacting employees if it does reoccur.
Certain issues will inevitably slip through the cracks and become incidents. But a proactive engine will make these incidents fewer and far between, and your IT team will have the tools to react to them swiftly and minimize their impact on the workplace experience.
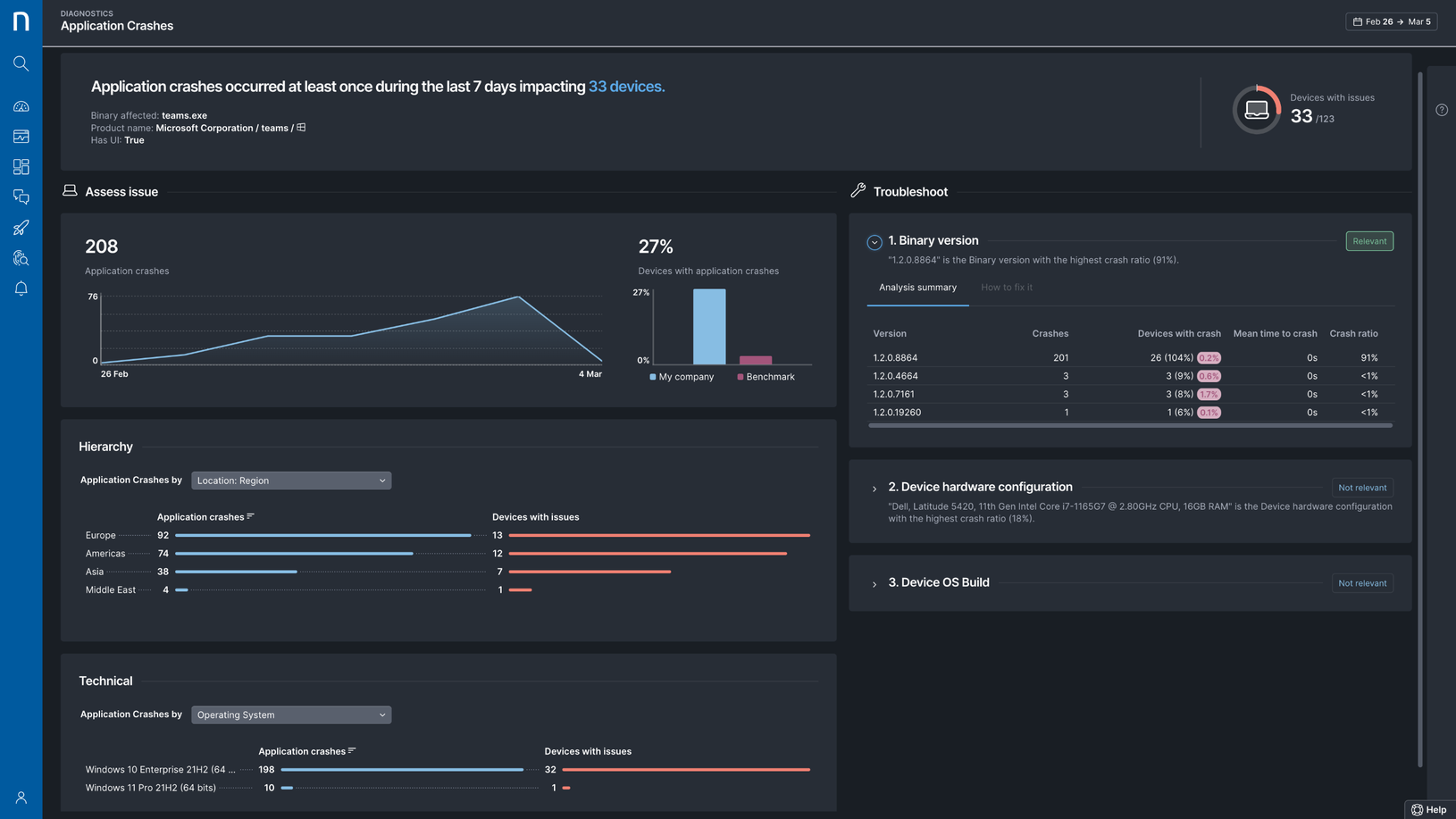
Nexthink Infinity provides real-time visibility into devices, applications, networks, and more. By capturing and visualizing event-level data, Infinity shows IT the complete reality of what is affecting employees. Powerful AI-driven analytics and visualizations automatically assess the scope and impact on employees across all locations, devices, applications, and technologies.
Step 3: Accelerate Reactive Incident Resolutions
Improve Support Efficiency
The right tools and technology empower the Support team to perform more efficiently. It enables them to solve more problems and issues faster and easier. As the repetitive/mundane support tasks are identified and automated, the support teams face more new challenges and the right tools to dress them make the whole workforce motivated and productive.
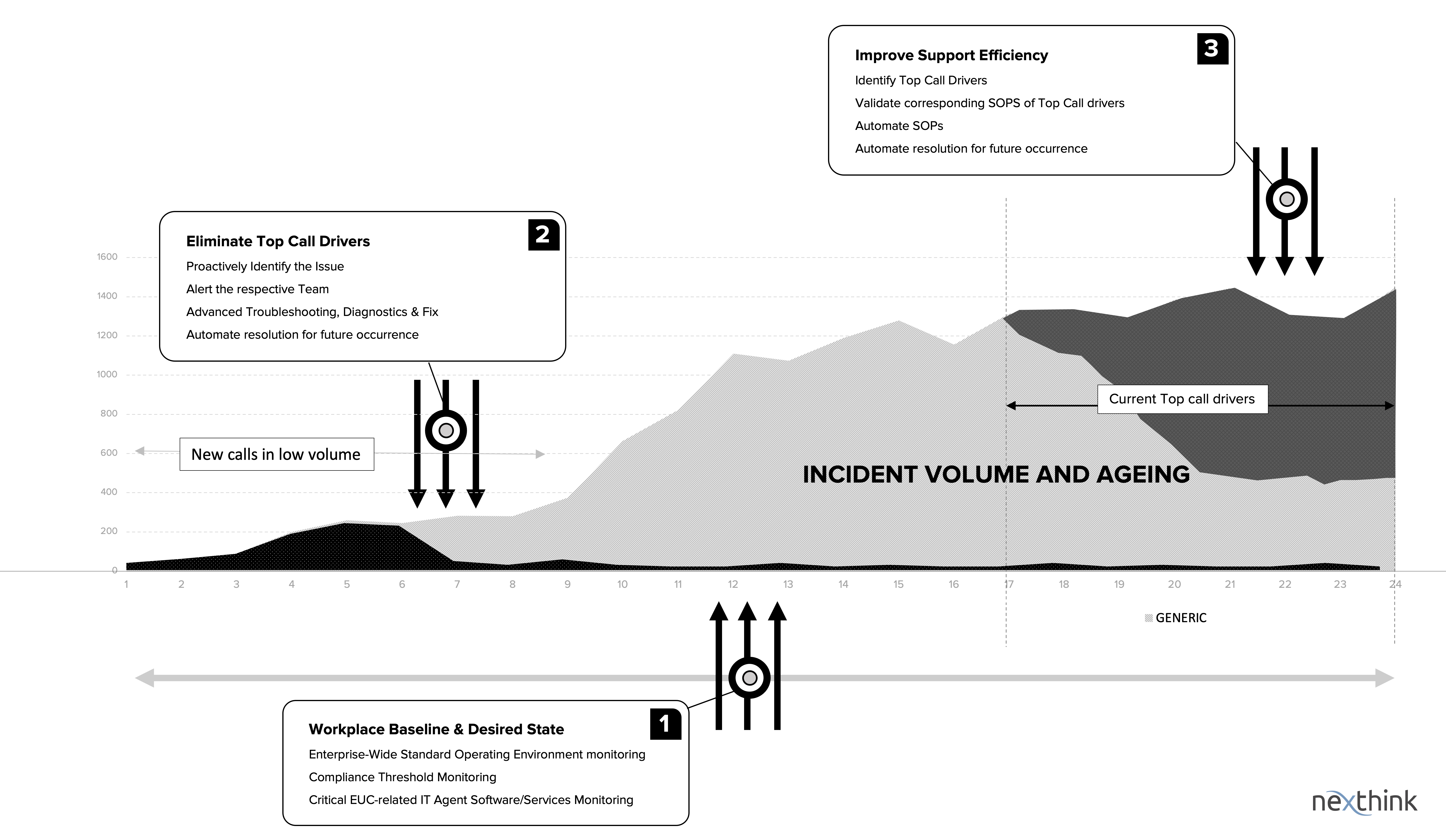
With the technology helping Support Analysts to identify issues proactively and fix them, also with the ability to automate critical and mundane IT tasks, now we can eliminate a significant amount of user-initiated incidents.
15% -25% top call driving incidents can be addressed and can be eliminated from recurring again.
Nexthink infinity empowers all stakeholders to solve more complex issues faster, drive down the MTTR and AHTs, as well as shift-left the issues and problems closer to the source. With the introduction of Self-help and Self-Heal Automation, Nexthink Infinity enables us to provide additional automated support channels, for End, User Automated Resolution, Self-Healing Devices, and Proactively Mass heal problems before they occur in the future.
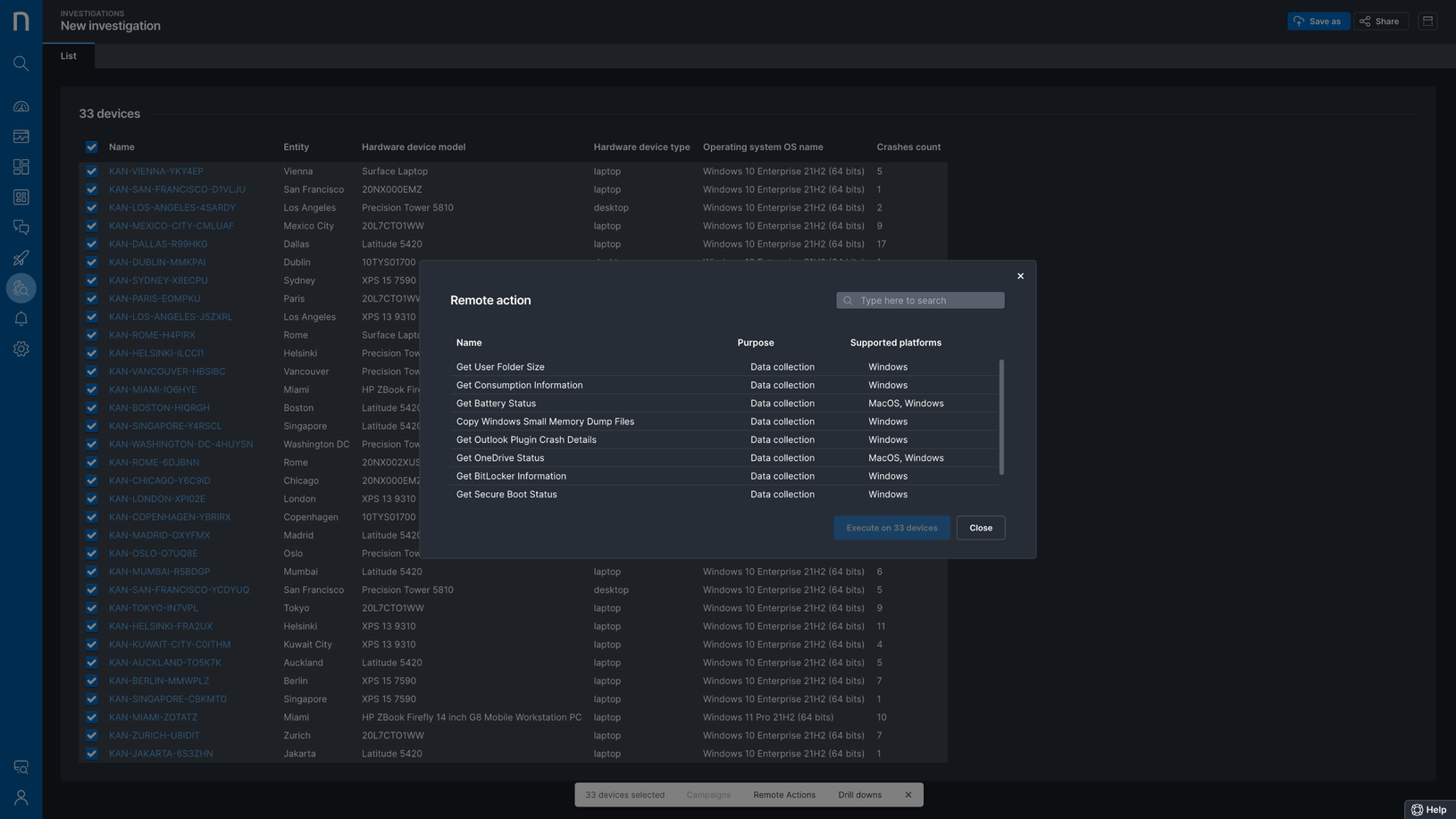
With this approach, we could effectively shift support from, the costly constructs of traditional onsite service, to a more cost-effective model that drives issues and incident resolution closer to the source, in fact even eliminating them much before they occur.
Embracing a proactive mindset doesn’t mean ditching your entire IT strategy and starting over. Unexpected issues will always occur, which means reactive problem-solving will always be a fundamental part of a well-run IT team. But when you bolster your IT framework from within, through workplace standardization and ongoing monitoring, the total number of incidents you’ll have to react to will drop significantly.
—
If you’re interested in learning how to save costs and improve your employee technology experience, then contact us today.
Related posts:
- The Ultimate List of Digital Employee Experience Job Titles
- 3 Steps For A More Strategic Approach to Incident Reduction
- IT & The Flow State: 5 Ways IT Can Facilitate The Flow State at Work
- 5 Ways to Reduce the IT Incident Backlog Before Your Team Gets Crushed
