What autonomous AI agents mean for Enterprise IT


Autonomous AI agents are getting real.
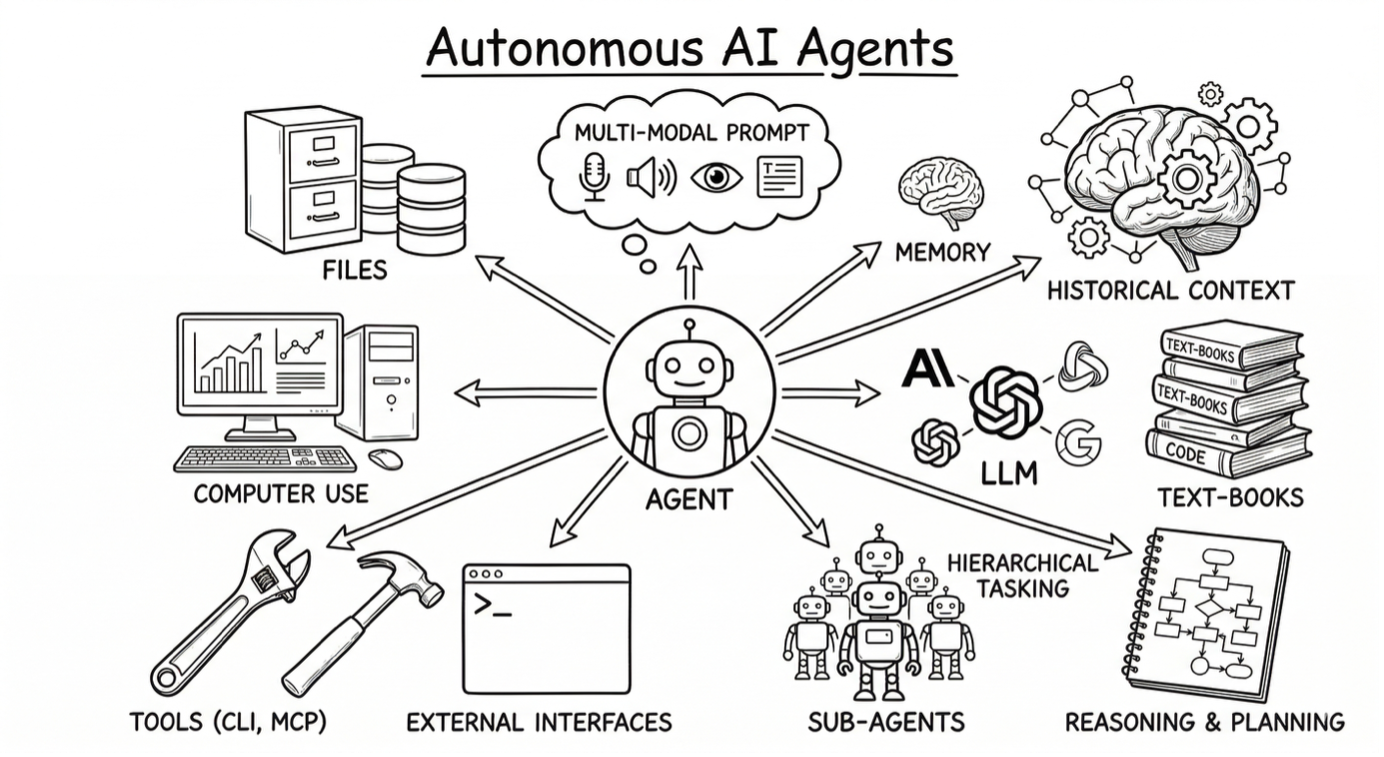
AI agents can now take control of a machine without human supervision.
They can dynamically write and run code, call OS-native tools, observe execution feedback, recover from errors and retry inside a controlled execution environment.
OpenClaw made that shift visible: an open-source personal automation agent that showed how quickly and easily we can build powerful AI agents. Nvidia followed with NemoClaw, adding privacy and security guardrails that push the architecture closer to enterprise requirements.
At the same time, coding agents such as Claude Code and OpenAI Codex transformed software engineering. They inspect large codebases, edit across many files, run tools, and iteratively converge on working changes.
Different use cases. Rapid adoption. Same underlying shift: agents that write code and act, not just advise.
In this article, we introduce a lightweight prototype for autonomous IT troubleshooting. We use it to show how these agents must evolve to become useful and safe in enterprise IT. Our argument is simple: local autonomy alone is not enough. Enterprise deployment requires a runtime safety layer and an enterprise learning layer.
What changed technically?
Since late 2025, LLM coding capability has stepped up, driven by post-training with verifiable rewards (RLVR). Unlike traditional RLHF, which relies on subjective, expensive human preference judgments, RLVR trains on domains where correctness is automatically verifiable. The model gets a binary or graded reward: Code either passes the tests or it doesn't.
Combining this with a better use of execution feedback (errors/logs), and agentic loops (edit → run → fix) turns code generation from a one-shot prediction problem into a system that can explore and adapt while solving the task.
That is why personal automation agents and coding agents are becoming capable and can act as smart IT technicians for a single endpoint.
Why this matters for enterprise IT, and why local execution is not enough
This shift changes what is possible in IT: agents that autonomously investigate issues, write and locally execute arbitrary code, and iterate without waiting for a human.
They can generate Bash scripts, PowerShell, or diagnostic routines on the fly.
That expands the range of issues an AI agent can remediate: if a skilled technician could script it in hours, the agent can now script itself in seconds.
That same capability also makes them dangerous: arbitrary code execution on a managed endpoint is one of the highest-risk operations in IT security.
More autonomy without guardrails is a liability. Reducing that risk requires a new runtime safety layer: sandboxed execution that isolate agent actions from the broader system, and human-in-the-loop review gates for high-risk code before it runs.
The second missing layer is the enterprise learning. A local agent solves one issue on one device. This is not enterprise IT. An enterprise system turns that solution into a reusable capability, deployed across the fleet, governed by policy, and fed into collective learning. The real value is a self-improving system that gets smarter with every incident.
What we have built for IT teams
We built the PoC as a lightweight agent runtime embedded directly in the Nexthink Collector. The runtime is written in Rust to minimize footprint: the added binary size is under 4 MB.
The core runtime consists of a main agent that process requests and routes them to the appropriate sub-agent. Each sub-agent is configured remotely by the IT administrator through a dedicated UI and is defined by the following properties:
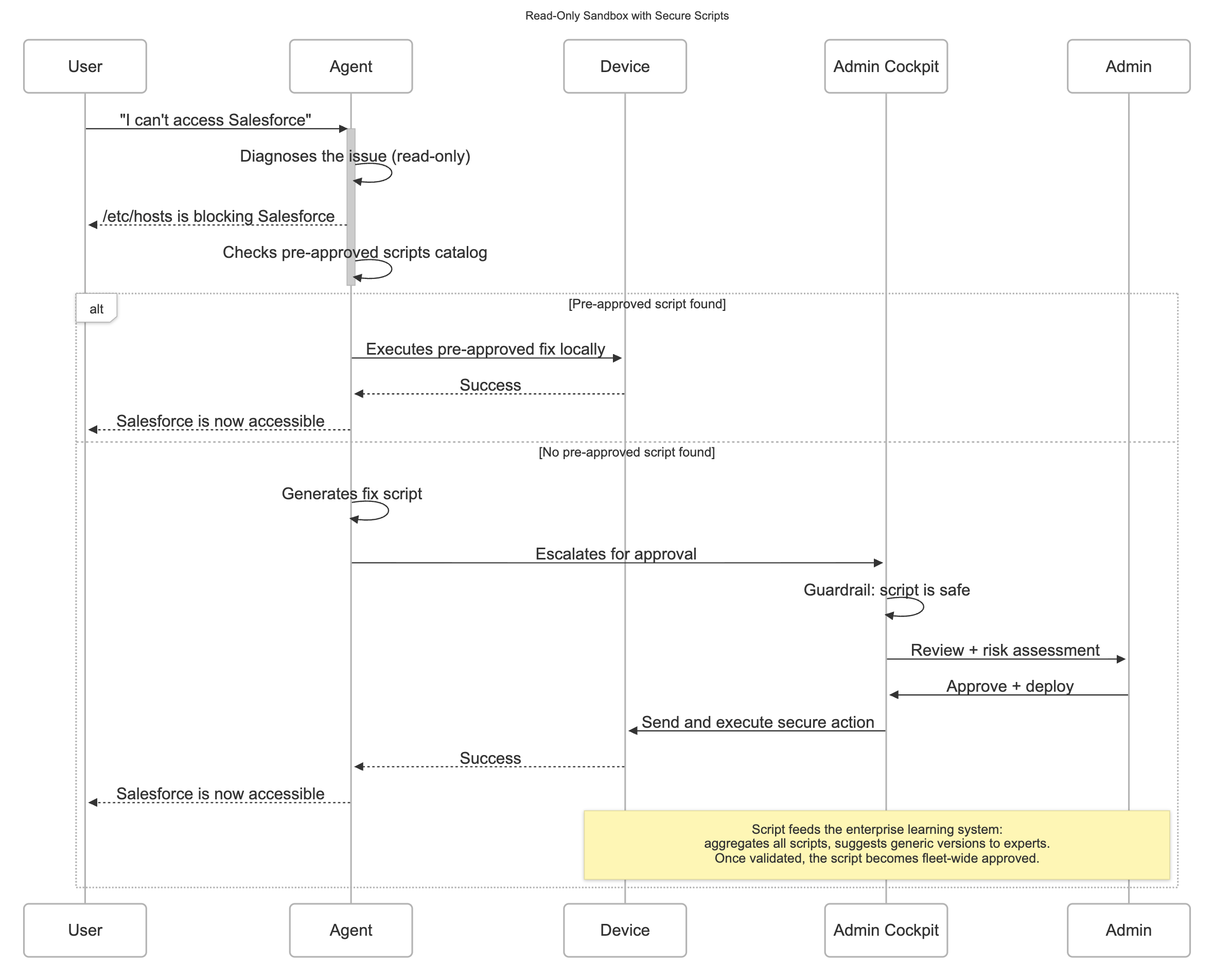
Sandbox the execution scope the agent is allowed to operate in. For example, a read-only sandbox can inspect system state but cannot modify files or access the network.
Windows: we run PowerShell scripts in a hardened environment that restricts language complexities and allows a safe subset of diagnostic cmdlets
MacOS: each command runs inside Apple's built-in Seatbelt kernel sandbox, where an SBPL profile enforces deny rules at the OS level before the process executes.
- Capabilities package skills and a list of tools (e.g., CLI commands) available to that sub-agent and aligned with its operational role.
Trigger is a schedule or system conditions that activate the agent.
Assigned model: the LLM selected for that role, balancing latency, cost, and capability. In our prototype, the main agent uses a frontier model (Opus 4.6), while lower-tier support agents use smaller models optimized for speed (Haiku).
We have also built the runtime safety layer around these core components
Secure script executor: running as a separate daemon, isolated from the agent process, with privilege execution.
Secure script agent checks if a secure script from the enterprise library already solves the user's issue. If so, it schedules the fix, no admin escalation needed. It can call secure script executor for actions already in the enterprise library.
Guardrails check script safety before admin review or direct execution
Enterprise Learning Layer
When AI agents operate in isolation and rely only on local memory, they are likely to repeat the same mistakes across devices and lose the opprtunity to learn from related incidents. They cannot accumulate the shared knowledge needed to improve the system as a whole.
Enterprise learning is like aviation safety. A pilot can manage one incident, but the industry improves when incidents are aggregated, compared, and converted into procedures that protect every future flight.
The strongest architecture pairs secure local execution with a central enterprise learning layer. The local agent handles the immediate incident: it inspects logs, queries the OS, runs network commands, generates diagnostic code, and attempts a sandboxed remediation on the device itself. The central layer creates the compounding value of enterprise learning. It captures the incident context, the actions taken, the outcome, and any human validation, then uses that evidence to identify reusable patterns across the fleet.
Consider a VPN issue on an employee laptop. A local agent may determine that the failure is caused a stale client configuration, or a DNS resolution problem, and it may fix that one machine safely. A central system can detect that similar failures are appearing on hundreds of devices with the same client version, correlate them with a recent policy change, and promote a validated remediation script for a fleet-wide remediation. What was a single repair becomes a reusable capability that enables proactive remediation.
We already see value in a pragmatic first generation of enterprise learning. Teams at Nexthink are building capabilities around memory and reusable skills that help agents retain context and apply past successful resolutions.
At the same time, we believe the broader problem requires deeper research. The challenge is not just aggregating incidents, but deciding which local fixes generalize, under what conditions they are useful and safe, and how they should be governed before reuse.
We will cover that enterprise learning in a follow-up post.
Conclusion
AI agents can now investigate and fix IT issues on their own. That's a real shift, but autonomy alone isn't enough for the enterprise.
A safety layer with sandboxed execution, restricted permissions, and human review keeps agents from doing harm. An enterprise learning layer ensures fixes don't stay on one machine but get captured, validated, and reused across the fleet.
One layer keeps agents safe, the other makes them smarter. Together, they turn a local agent into an enterprise system that improves with every incident.
